Introduction
PyTorch is a versatile and widely-used framework for deep learning, offering seamless integration with GPU acceleration to significantly enhance training and inference speeds. This guide walks you through setting up PyTorch to utilize a GPU, using Google Colab—a free platform with GPU access—as an example environment. You’ll learn how to verify GPU availability, manage tensors and models on the GPU, and train a simple neural network. Along the way, we’ll highlight essential commands for debugging and optimizing GPU usage, ensuring you’re equipped to harness the full power of PyTorch for your deep learning projects.
Table of Contents
Setup: Using Google Colab
Google Colab provides an easy and free way to access GPUs. Follow these steps:
- Go to Google Colab.
- Create a new notebook.
- Click on
Runtime > Change runtime type. - Set Hardware accelerator to GPU and save.
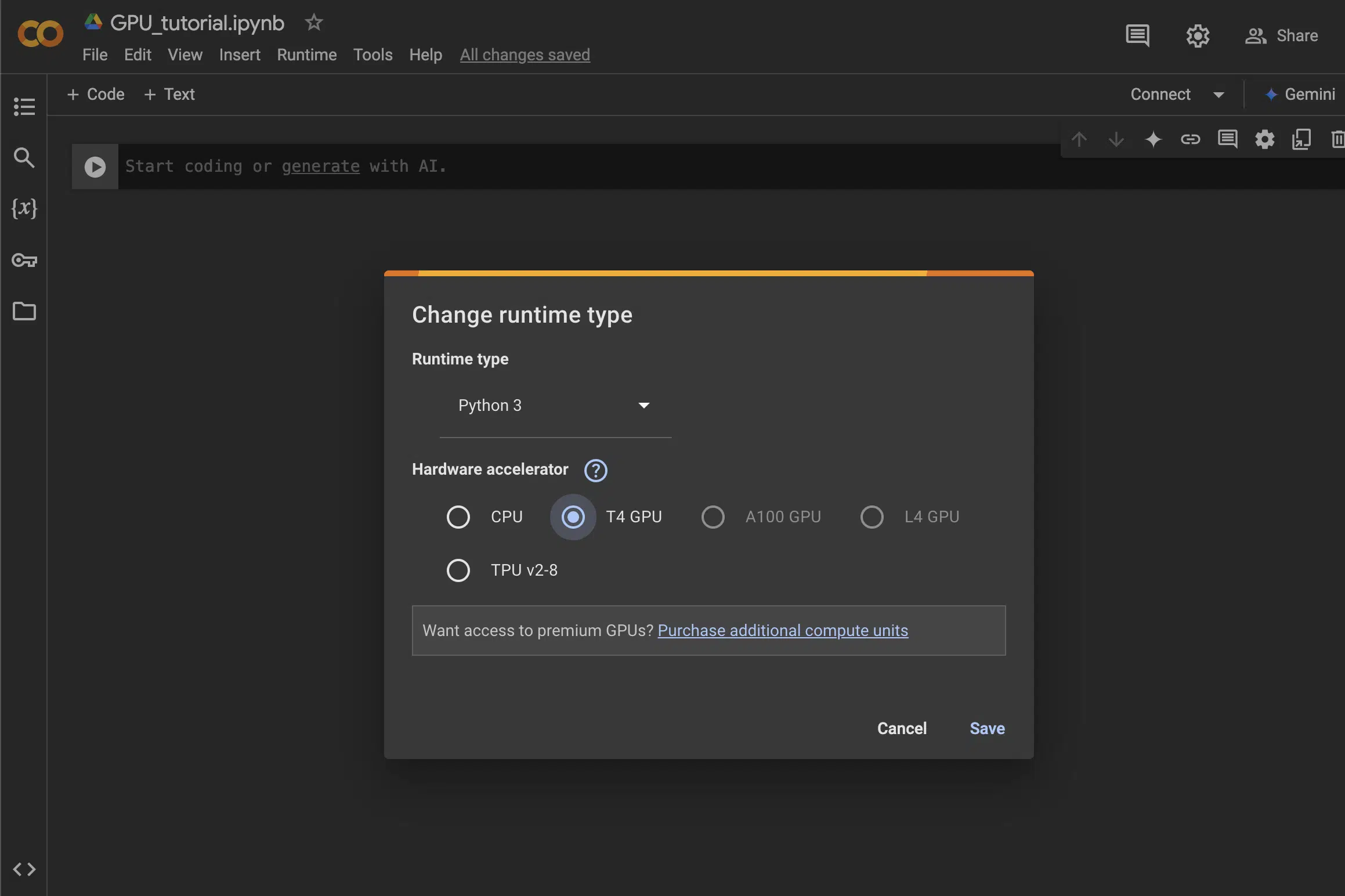
Note: You can also use Kaggle or cloud services like AWS if you prefer more control.
Installing PyTorch
PyTorch can be installed using pip. Execute the following command in a Colab notebook:
!pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118Verifying GPU Access
After installation, you can verify that PyTorch detects the GPU with the following code:
import torch
# Check if CUDA (GPU support) is available
print(torch.cuda.is_available())
# Get the name of the GPU
if torch.cuda.is_available():
print(torch.cuda.get_device_name(0))TrueTesla T4
Neural Network Training Example
In this section, we train a Convolutional Neural Network (CNN) on the CIFAR-10 dataset using PyTorch. The purpose of this example is to demonstrate the process of:
- Loading and preprocessing a dataset.
- Defining a neural network architecture dynamically to adapt to input data.
- Using GPU acceleration to speed up training.
- Comparing training performance on CPU and GPU.
Let’s break it down step by step:
1. Defining the Convolutional Neural Network (CNN)
CNNs are designed to process grid-like data such as images. Here, we define a simple CNN with two convolutional layers, a max-pooling layer, and two fully connected layers. The key components are:
- Convolutional Layers: Extract features from the input images.
- Pooling Layer: Reduces the spatial dimensions of the feature maps, making the network more efficient.
- Fully Connected Layers: Perform the final classification based on the extracted features.
The network dynamically computes the size of the feature map after convolution and pooling operations, ensuring flexibility for different input sizes:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import time
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2) # Halves the dimensions
self.flattened_size = None # To calculate dynamically
self.fc1 = None
self.fc2 = nn.Linear(256, 10) # Placeholder for final classification
def forward(self, x):
x = torch.relu(self.conv1(x))
x = self.pool(torch.relu(self.conv2(x))) # Reduce dimensions
if self.flattened_size is None:
self.flattened_size = x.shape[1] * x.shape[2] * x.shape[3]
self.fc1 = nn.Linear(self.flattened_size, 256).to(x.device) # Define fully connected layer dynamically
x = x.view(-1, self.flattened_size) # Flatten the feature map
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
2. Loading the CIFAR-10 Dataset
CIFAR-10 is a popular image classification dataset with 10 classes. Each image is a 32×32 pixel RGB image. To prepare this dataset for training:
- We use
torchvision.datasets.CIFAR10to download and load the dataset. - We normalize the images to improve convergence during training.
- A
DataLoaderis used to efficiently batch and shuffle the dataset during training.
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # Normalize pixel values
])
train_dataset = datasets.CIFAR10(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=128, shuffle=True)
3. Training the Model
The training process involves several steps:
- Move the Model and Data to the Device: The model and tensors are moved to the CPU or GPU based on availability.
- Define the Loss Function and Optimizer: CrossEntropyLoss is used for classification, and the Adam optimizer updates the model’s weights.
- Training Loop: The loop iterates over batches of data, computes the loss, backpropagates gradients, and updates weights.
def train_cnn(device, epochs=2):
# Load CIFAR-10 dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.CIFAR10(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=128, shuffle=True)
# Initialize model, loss function, and optimizer
model = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
start_time = time.time() # Start timing
# Training loop
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
elapsed_time = time.time() - start_time # End timing
print(f"Training completed on {device} in {elapsed_time:.2f} seconds")
return elapsed_time # Ensure the time is returned
4. Measuring Performance on CPU and GPU
Finally, we compare the training times on the CPU and GPU. By timing the training loop, we can observe the speedup achieved with GPU acceleration:
if __name__ == "__main__":
print("Training on CPU:")
cpu_device = torch.device("cpu")
cpu_time = train_cnn(cpu_device)
if torch.cuda.is_available():
print("\nTraining on GPU:")
gpu_device = torch.device("cuda")
gpu_time = train_cnn(gpu_device)
print(f"\nSpeedup: {cpu_time / gpu_time:.2f}x")
Files already downloaded and verified
Epoch 1, Loss: 1.6400560140609741
Epoch 2, Loss: 1.4146881103515625
Training completed on cpu in 383.70 seconds
Training on GPU:
Files already downloaded and verified
Epoch 1, Loss: 1.5669273138046265
Epoch 2, Loss: 1.4080666303634644
Training completed on cuda in 28.96 seconds
Speedup: 13.25x
The results show the significant speedup achieved by leveraging GPU acceleration. While the CPU is sufficient for small-scale experiments, GPUs become essential for larger datasets and more complex models.
GPUs are well-suited for Convolutional Neural Networks (CNNs) because they excel at parallel processing. CNNs involve operations like convolution and matrix multiplications, which require processing large volumes of data simultaneously across multiple layers and channels. GPUs are designed with thousands of cores optimized for handling these tasks concurrently, making them significantly faster than CPUs for such workloads. Additionally, GPUs efficiently manage the repeated computation patterns inherent in CNNs, such as applying filters across images, which further enhances their performance in deep learning.
Tip: You can adjust the batch size, learning rate, or the number of epochs to see how they affect performance.
Note: The speedup observed in this example may differ on different GPUs or configurations. Always profile your model and dataset to optimize for your specific hardware and workload.
GPU Memory Management
PyTorch provides useful commands to query and manage GPU resources. Below are some examples to better understand GPU usage and memory allocation:
# Check if PyTorch sees any GPUs
print("GPU Available:", torch.cuda.is_available())
# Get the number of GPUs available
print("Number of GPUs:", torch.cuda.device_count())
# Get the current GPU device ID
print("Current GPU Device ID:", torch.cuda.current_device())
# Get the device name
print("GPU Name:", torch.cuda.get_device_name(0))
# Maximum GPU memory cached (convert to MB and GB)
max_memory_cached = torch.cuda.max_memory_reserved(0)
print(f"Maximum GPU Memory Cached: {max_memory_cached / 1024 / 1024:.2f} MB ({max_memory_cached / 1024 / 1024 / 1024:.2f} GB)")
# Current GPU memory allocated (convert to MB and GB)
memory_allocated = torch.cuda.memory_allocated(0)
print(f"Current GPU Memory Allocated: {memory_allocated / 1024 / 1024:.2f} MB ({memory_allocated / 1024 / 1024 / 1024:.2f} GB)")Number of GPUs: 1
Current GPU Device ID: 0
GPU Name: Tesla T4
Maximum GPU Memory Cached: 342.00 MB (0.33 GB)
Current GPU Memory Allocated: 16.25 MB (0.02 GB)
These commands help monitor and debug GPU usage during training. For example, you can use torch.cuda.memory_allocated() to track how much memory is being used by your model and tensors.
Understanding GPU Queries in PyTorch
PyTorch provides several helpful commands to check GPU availability and ensure that tensors and models are stored on the GPU. This section explains how to use these commands effectively, including addressing deprecations in recent versions.
Common GPU Queries and Commands
When working with GPUs in PyTorch, it’s crucial to confirm that your system and code are utilizing the GPU correctly. The following table provides a list of commonly used queries and commands to check GPU availability, manage device settings, and ensure that your tensors and models are allocated on the GPU. These commands are particularly useful for debugging, optimizing performance, and avoiding errors related to CPU-GPU data transfers.
Each query serves a specific purpose:
- Availability Checks: Use commands like
torch.cuda.is_available()to confirm that PyTorch detects a GPU on your system. - Device Allocation: Commands such as
torch.set_default_device("cuda")help ensure that new tensors are automatically allocated to the GPU by default. - Tensor and Model Checks: Verify whether specific tensors or models are stored on the GPU with
my_tensor.is_cudaorall(p.is_cuda for p in my_model.parameters()).
The table below summarizes these commands, making it easier to refer to them during your PyTorch development workflow:
| Query | Command |
|---|---|
| Does PyTorch see any GPUs? | torch.cuda.is_available() |
| Are tensors stored on GPU by default? | torch.rand(10).device |
| Set default device to CUDA (recommended): | torch.set_default_device("cuda") |
| Set default dtype for tensors: | torch.set_default_dtype(torch.float32) |
| Is this tensor a GPU tensor? | my_tensor.is_cuda |
| Is this model stored on the GPU? | all(p.is_cuda for p in my_model.parameters()) |
Examples of GPU Queries
Below are updated code snippets reflecting the latest PyTorch recommendations for managing default device and tensor types:
import torch
# Check if PyTorch sees any GPUs
print("GPU Available:", torch.cuda.is_available())
# Check the device of a random tensor
random_tensor = torch.rand(10)
print("Tensor Device:", random_tensor.device)
# Set default device to CUDA (if GPU is available, recommended method)
if torch.cuda.is_available():
torch.set_default_device("cuda")
print("Default device set to CUDA")
# Set default dtype for tensors (optional, recommended for PyTorch 2.1+)
torch.set_default_dtype(torch.float32)
# Check if a specific tensor is on the GPU
print("Is tensor on GPU?", random_tensor.is_cuda)
# Define a simple model and check if all parameters are on GPU
model = torch.nn.Linear(10, 1).to("cuda" if torch.cuda.is_available() else "cpu")
print("Is model on GPU?", all(p.is_cuda for p in model.parameters()))
Tensor Device: cuda:0
Default device set to CUDA
Is tensor on GPU? True
Is model on GPU? True
Note: Starting from PyTorch 2.1, torch.set_default_tensor_type() is deprecated. Use torch.set_default_device() for setting the default device and torch.set_default_dtype() for setting the default tensor type.
Tip: Use these commands during development to ensure your tensors and models are correctly allocated on the GPU, avoiding performance issues due to CPU-GPU transfers.
Additional Free Platforms for GPU Usage
Besides Google Colab, several other platforms offer free or low-cost GPU access for deep learning experiments. These platforms are great alternatives if you encounter session limits or GPU availability issues on Colab. Here are some options:
- Kaggle Notebooks: Kaggle provides free Jupyter Notebook environments with access to GPUs. Each session offers up to 30 hours of GPU usage per week, making it a viable alternative for running deep learning experiments.
- Codesphere: Codesphere offers cloud-based development environments that support GPU-accelerated instances, enabling efficient training and deployment of machine learning and deep learning models directly from the platform.
- Paperspace: Paperspace is a cloud computing platform that provides GPU-accelerated virtual machines and development environments, facilitating efficient training and deployment of machine learning and deep learning models.
- AWS Sagemaker: Amazon SageMaker is a fully managed service that enables developers and data scientists to build, train, and deploy machine learning models at scale, offering support for GPU-accelerated instances to enhance performance for computationally intensive tasks.
Tip: Always check the runtime limits and resource allocations of these platforms to ensure they meet the requirements of your project.
Warning: Free platforms may experience high demand, leading to delays or reduced performance. Consider switching to paid tiers or cloud providers like AWS, Azure, or Google Cloud for large-scale training tasks.
Conclusion
This example demonstrated how to train a neural network on a GPU using PyTorch. Leveraging GPU acceleration can drastically reduce training times, making it an essential tool for deep learning practitioners. By offloading computationally intensive operations to the GPU, you can work with larger datasets and more complex models, which would be infeasible on a CPU.
However, there are some important points to keep in mind:
- Device Compatibility: Ensure that both your hardware and software support CUDA if you plan to train on a GPU. Check compatibility between PyTorch, CUDA, and your GPU drivers.
- Memory Management: Monitor GPU memory usage during training, especially with larger models and datasets. Out-of-memory errors can occur if the model or batch size exceeds the available GPU memory. Use
torch.cuda.memory_allocated()andtorch.cuda.max_memory_reserved()to debug memory issues. - Default Device Behavior: Tensors and models are not automatically allocated to the GPU. Always use
.to(device)or equivalent to explicitly place them on the correct device. - Free Platforms: When using free platforms like Google Colab, be mindful of session time limits, potential disconnections, and GPU availability constraints. Save your progress frequently to avoid losing work.
Tip: For long-running tasks, consider using a local GPU setup or cloud services with persistent sessions for uninterrupted training.
Warning: Always validate that your model and tensors are correctly allocated on the GPU. Failing to do so can lead to unexpected performance bottlenecks as data is transferred between the CPU and GPU during training.
Congratulations on reading to the end of this tutorial!
For further reading, please go through the links provided in the section below.
Further Reading
-
PyTorch Documentation: torchvision.datasets
Official documentation for loading and using datasets in PyTorch, including CIFAR-10 and other popular datasets.
-
PyTorch Documentation: torch.nn.Conv2d
Detailed documentation for the
torch.nn.Conv2dmodule, which is used for defining convolutional layers in neural networks. -
PyTorch CUDA Semantics
Official notes on CUDA usage in PyTorch, covering best practices and device management.
-
The Research Scientist Pod Deep Learning Frameworks Page
An in-depth overview of various deep learning frameworks, including PyTorch, TensorFlow, and others, to help you choose the right tool for your project.
If you found this guide helpful, feel free to link back to this post for attribution and share it with others exploring GPU acceleration in PyTorch!
HTML: Attribution: The Research Scientist Pod – Accelerating Deep Learning with PyTorch and GPUs: A Beginner’s Guide
Markdown: [The Research Scientist Pod – Accelerating Deep Learning with PyTorch and GPUs: A Beginner’s Guide](https://researchdatapod.com/accelerating-deep-learning-pytorch-gpus-beginners-guide/)
Have fun and happy researching!

Suf is a senior advisor in data science with deep expertise in Natural Language Processing, Complex Networks, and Anomaly Detection. Formerly a postdoctoral research fellow, he applied advanced physics techniques to tackle real-world, data-heavy industry challenges. Before that, he was a particle physicist at the ATLAS Experiment of the Large Hadron Collider. Now, he’s focused on bringing more fun and curiosity to the world of science and research online.