
Understanding the similarity between two objects is a universal problem. In machine learning, you can use similarity measures for various issues. These include object detection, classification and segmentation tasks in computer vision and similarity between text documents in natural language processing.
Jaccard Similarity, also known as the Jaccard Index and Intersection of Union, is the most intuitive and straightforward similarity measure.
Table of contents
Jaccard Similarity Formula

The Jaccard Similarity is a term coined by Paul Jaccard, defined as the size of the intersection divided by the size of the union of two sets. In simple terms, we can determine the Jaccard Similarity as the number of objects the two sets have in common divided by the total number of objects. If two datasets share the same members, the Similarity term will be 1. Conversely, if the two sets have no members in common, then the term will be 0.
Visualization of Jaccard Similarity
Let’s describe the mathematical definition visually. If we take two distinct sets: Set 1 and Set 2, they are always themselves and self-contained regardless of how they are combined with other sets, as shown below.
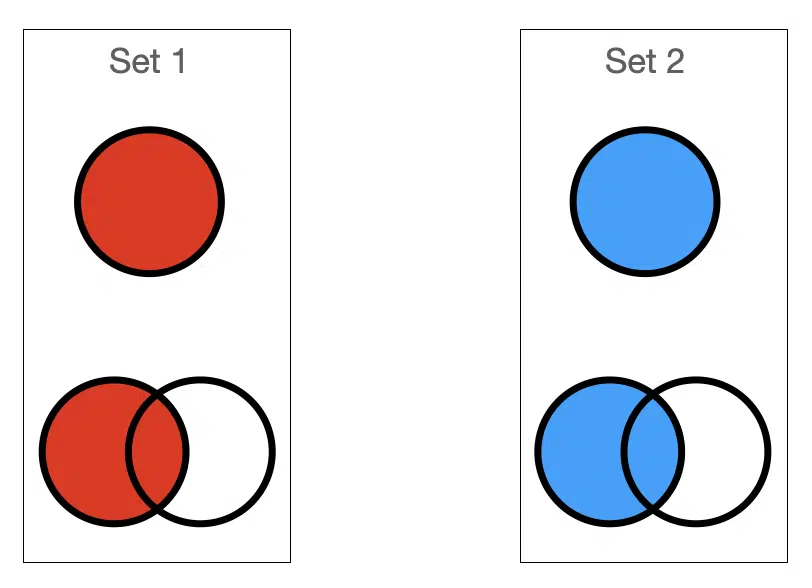
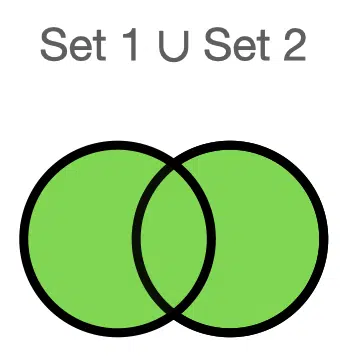
We can describe everything contained in the two sets, the union and represent by the symbol $latex \cup $. We count the objects occurring in both sets once since the union considers both sets together.
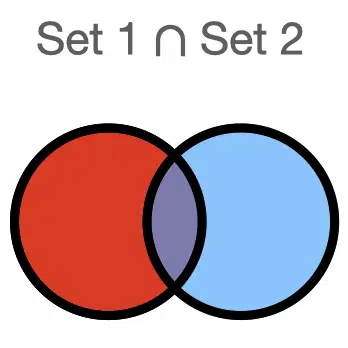
We then describe the overlap between the sets, which is called the intersection between sets and is represented by the symbol $latex \cap $.
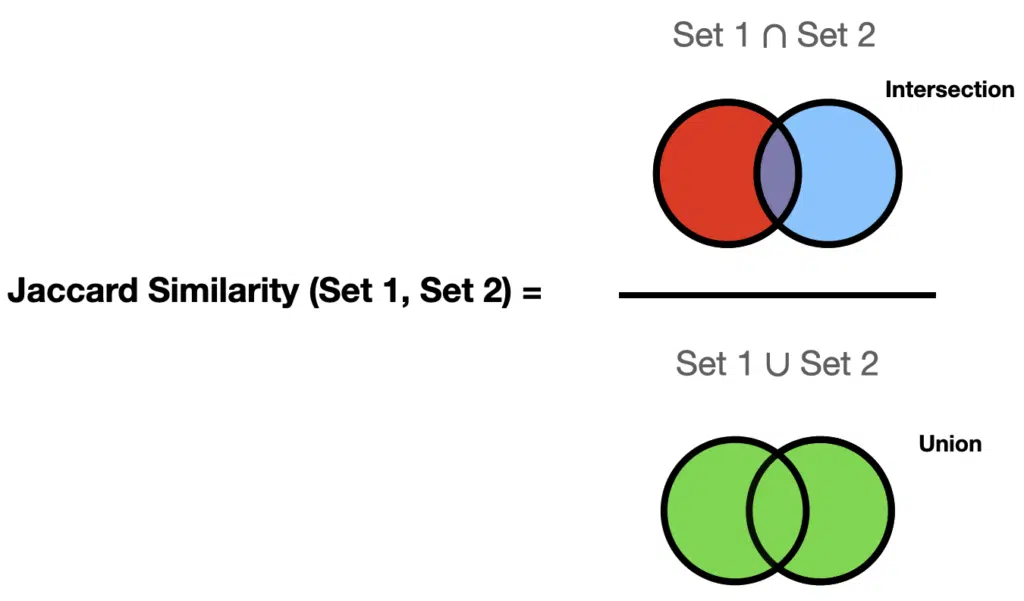
Now we have described the individual components of Jaccard Similarity; we can put them together to get Jaccard similarity = (number of objects in common) / (total number of objects):
The Jaccard Distance
The Jaccard distance measures the dissimilarity between sets, is complementary to the Jaccard Similarity, and is obtained by subtracting the Jaccard coefficient from 1, or equivalently by dividing the difference of the size of the union and the intersection of two sets by the size of the union:
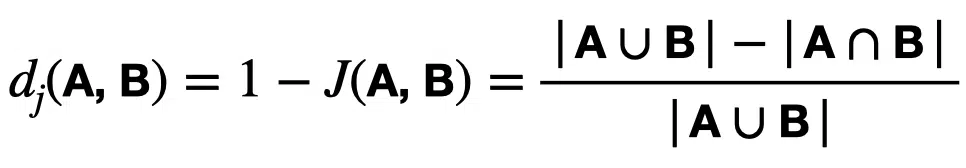
The distance is a metric on the collection of all finite sets. We can use the distance to calculate an n $latex \times$ n matrix for clustering and multidimensional scaling of n sample sets.
Jaccard Similarity for Two Binary Variables
A binary variable is a variable that can occupy two states. A binary variable is asymmetric if the outcome of the states is not equally important. To give an example, we are trying to determine customers’ buying behaviour in a grocery store. The binary attribute we are recording is a particular item bought at the store, where “1” indicates purchasing the item and “0” means not purchasing the item.
Given the volume of items in a typical grocery store, a far higher number of items will not be bought by any given customer at a time compared to items that the customer buys. Therefore, the collection of items purchased is an asymmetric binary variable because 1 is more important than 0. When computing the similarity in behaviour between customers, we want to consider buying items.
We need to extract four quantities, using the binary data vectors, for the first step in calculating the Jaccard Similarity between customers:
- w = the number of elements equal to 1 for both binary vectors i and j
- x = the number of elements equal to 0 for vector i but equal 1 for object j
- y = the number of elements equal to 1 for vector i but equal 0 for object j
- z = the number of elements that equal 0 for both vectors i and j.
We can define the Jaccard Similarity using these quantities with the following equation:
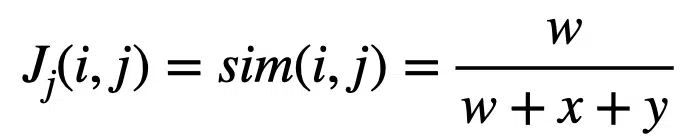
We discard the 0 matches under the asymmetric binary assumption that they are not important for this computation.
Considering the following table of purchases for three customers:
| Name | Fruit 1 | Fruit 2 | Fruit 3 | Fruit 4 | Fruit 5 | Fruit 6 | Fruit 7 |
|---|---|---|---|---|---|---|---|
| Paul | 0 | 1 | 1 | 0 | 0 | 0 | 1 |
| Leto | 1 | 0 | 1 | 0 | 1 | 1 | 0 |
| Aria | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
We can calculate the similarity between each pair as follows:
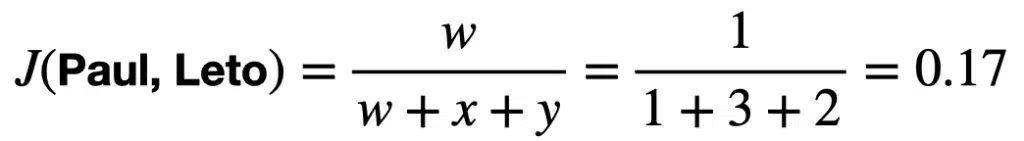
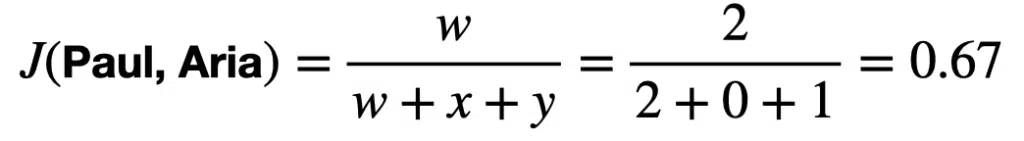
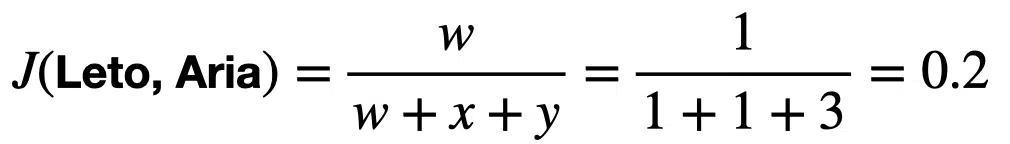
These similarity results suggest that Paul and Aria have similar shopping behavior. Paul and Leto and Leto and Aria have dissimilar shopping behavior.
Python Example of Jaccard Similarity
We can code up the example above in Python using Numpy arrays. We can also find Jaccard Similarity using the built-in scikit-learn function sklearn.metrics.jaccard_score. Go to this article for more helpful Python libraries for data science and machine learning.
def jaccard_score(x, y):
"""Function for finding the similarity between two binary vectors"""
intersection = np.logical_and(x,y)
union = np.logical_or(x,y)
J = intersection.sum() / float(union.sum())
return J
# Define customer purchase behavior vectors
paul = [0, 1, 1, 0, 0, 0, 1]
leto = [1, 0, 1, 0, 1, 1, 0]
aria = [0, 0, 1, 0, 0, 0, 1]
# Find the similarity between the vectors
sim_p_l = jaccard_score(paul, leto)Similarity between Paul and Leto is 0.16666666666666666
Similarity between Paul and Aria is 0.6666666666666666
Similarity between Leto and Aria is 0.2
Numerical Example of Jaccard Similarity on Sets
Let us consider two sets containing integers:
- {1, 3, 5, 7, 9}
- {0, 1, 2, 3, 4, 5, 6, 7}
We can calculate the Jaccard Similarity between the two sets as follows:
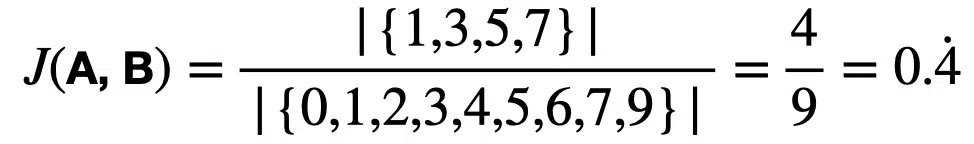
Python Function for Jaccard Similarity on Numerical Sets
We can define a function in Python to calculate the Jaccard Similarity between the two sets of data:
def jaccard_set(list1, list2):
"""Jaccard Similarity function for two sets"""
intersection = len(list(set(list1).intersection(list2)))
union = (len(list1) + len(list2)) - intersection
J = float(intersection) / union
return J
# Define two sets
x = [1, 3, 5, 7, 9]
y = [0, 1, 2, 3, 4, 5, 6, 7]
J = jaccard_set(x,y)
print('Jaccard Similarity between the two sets: ', J)Jaccard Similarity between the two sets: 0.4444444444444444
The function returns the same value as the manual calculation giving a Jaccard Similarity of 0.4 recurring.
Text Similarity
In Natural Language Processing, text similarity is a common method of assessing text documents. We can use several similarity metrics such as Cosine similarity, Jaccard similarity and Euclidean distance, each of which has its unique behavior. Let us consider two documents and determine their similarity using the Jaccard Similarity
doc_1 = "A beginning is the time for taking the most delicate care that the balances are correct"
doc_1 "A beginning is a very delicate time"
We can turn the documents into sets of unique words:
set_1 = {‘a’, ‘beginning’, ‘is’, ‘the’, ‘time’, ‘for’, ‘taking’, ‘most’, ‘delicate’, ‘care’, ‘that’, ‘balances’, ‘are’, ‘correct’}
set_2 = {‘a’, ‘beginning’, ‘is’, ‘very’, ‘delicate’, ‘time’}
The intersection over the union of the two sets is as, therefore:

Python Function for Jaccard Similarity on Text Documents
We can define a Python function for calculating the Jaccard Similarity for two text documents:
def jaccard_text(doc1, doc2):
"""Jaccard Similarity function for two text documents"""
# List the unique words in a document
words_doc_1 = set(doc1.lower().split())
words_doc_2 = set(doc2.lower().split())
# Find the intersection of words between documents
intersection = words_doc_1.intersection(words_doc_2)
# Find the union of words between documents
union = words_doc_1.union(words_doc_2)
# Jaccard Similarity
J = float(len(intersection)) / len(union)
return J
doc_1 = "A beginning is the time for taking the most delicate care that the balances are correct"
doc_2 = "A beginning is a very delicate time"
print('Jaccard similarity between the two documents is: ', jaccard_text(doc_1, doc_2))
Jaccard similarity between the two documents is: 0.3333333333333333As shown in the manual calculation, the similarity between the two text documents is 0.3 recurring. Jaccard similarity can be used for much larger sets than presented in this example.
Example of Jaccard Similarity in Machine Learning
In computer vision, convolutional neural networks are used for various tasks, including detecting and identifying objects in images. Any algorithm that provides a predicted bounded box as output can be evaluated using the Jaccard Similarity. Applying the Jaccard Similarity for an object detector requires a ground truth bounding box, the hand-labelled bounding box that specifies where the object is in the image, and the predicted bounding box from the model. You can see an example in the image below:
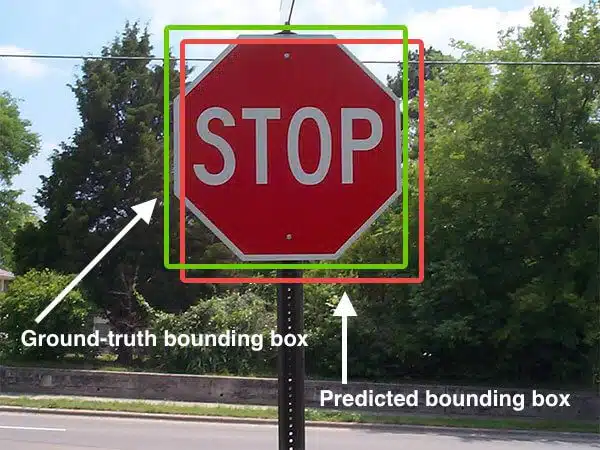
We can see that the object detector has detected the presence of a stop sign in the image. The predicted bounding box is in red, and the ground-truth bounding box is in green. We can determine the Jaccard Similarity or, in this case, Intersection over Union using:
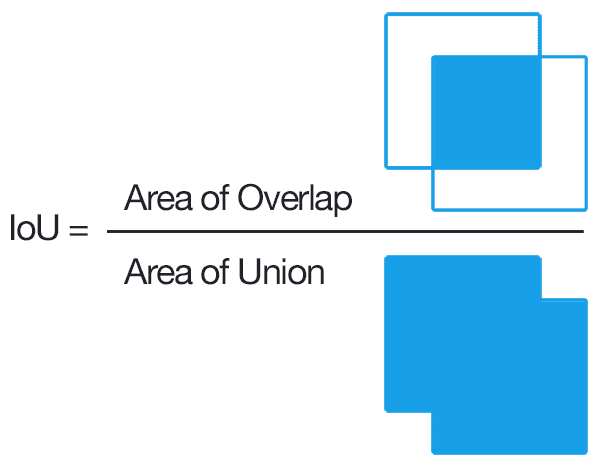
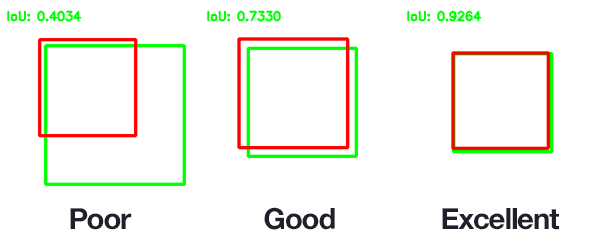
The higher the IoU value returned, the more the predicted bounding box aligns with the ground-truth bounding box and the more accurate the object detector algorithm. You can see examples of varying Jaccard Similarity in the figure below:
For further reading on using set intersection in Python go to the article: How to do Set Intersection in Python.
For further reading on using set union in Python go to the article: How to Do Set Union in Python.
Limitations of Jaccard Similarity
Sometimes when you are handling data, you will have missing observations, which makes calculating similarity difficult. You can do several things to overcome missing data points:
- Fill the missing data points with zeros
- Replace the missing value with the median value in the set
- Use a k-nearest neighbour algorithm or EM algorithm to interpolate
Summary
Jaccard Similarity provides a simple and intuitive method of finding the similarity between objects. This article shows that those objects can take on various types, including text documents, asymmetric binary vectors, and bounding boxes. You can now visualize Jaccard Similarity, calculate the value manually and write functions in Python to calculate it.
If you want to learn how to calculate the Jaccard similarity in R++, please visit our guide: How to Calculate Jaccard Similarity in R
If you want to learn how to calculate the Jaccard similarity in C++, please visit our guide: Set Similarity with Jaccard Coefficient and MinHash in C++.
If you want to learn how to implement string similarity metrics in Python, R, and C++, please visit our guide: Jaro-Winkler Similarity: A Comprehensive Guide to String Matching.
Thank you for reading to the end of this article. Have fun and happy researching! Stay tuned for more data science and machine learning tips and insight.

Suf is a senior advisor in data science with deep expertise in Natural Language Processing, Complex Networks, and Anomaly Detection. Formerly a postdoctoral research fellow, he applied advanced physics techniques to tackle real-world, data-heavy industry challenges. Before that, he was a particle physicist at the ATLAS Experiment of the Large Hadron Collider. Now, he’s focused on bringing more fun and curiosity to the world of science and research online.