Introduction
Part of my blog will cover the latest and most significant developments in machine learning research. My aim in these paper readings is to extract the key points, so you can easily digest what the research is contributing. I will go into some detail into the methods so that you get familiar with some advanced machine learning concepts. But these posts will be summaries, not paper rewrites. The best way to get the most out of a paper is to read it and read the referenced papers. Hopefully, this post will spark your curiosity about state-of-the-art machine learning and get you reading if you have not done so already. If you want to improve your knowledge base of machine learning and linear algebra concepts to get more out of paper readings, you can visit my blog post which provides the best books for machine learning. Now, on to BERT!
BERT [1] is an essential milestone in the progress of NLP and machine learning. The research paper written by Google AI Language remains one of the most cited and used pieces of research in recent times. Due to the model’s success, different flavors of BERT have been developed to add further strides to the innovation and state-of-the-art results observed.
Table of contents
TL;DR
- BERT (Bidirectional Encoder Representations from Transformers) was a groundbreaking, pre-trained, and unsupervised model that outperformed existing high-performance models on various NLP tasks when it was introduced in 2018
[1]. - It introduced bidirectional training of the Transformer model, which uses attention for language modelling and extracts more in-depth contextual information from natural language sequences
[1]. - BERT uses novel training methods like masked language modelling and next-sentence prediction, allowing for bidirectional unsupervised training
[1]. - While newer models have surpassed BERT, it remains a pivotal milestone in NLP and lays the groundwork for many subsequent advances.
Why Is BERT Important?
Before BERT, many language models were unidirectional, limiting their ability to capture context [2]. BERT addressed this by enabling bidirectional learning, allowing the model to consider both the left and right context for each word [1].
Critical advantages of BERT include:
- Improved context understanding: By considering bidirectional context, BERT captures more nuanced language representations
[1]. - Transfer learning for NLP: BERT demonstrated the power of pre-training and fine-tuning in NLP, similar to the impact of ImageNet on computer vision
[1]. - State-of-the-art performance: Upon release, BERT achieved top results on various NLP benchmarks, pushing the boundaries of what was possible in language understanding tasks
[3].
What Does BERT Do?
Transformer Architecture
The Transformer, introduced in the “Attention Is All You Need” paper [3], is a sequence-to-sequence model consisting of an encoder and a decoder. In the context of BERT:
- Encoder: Processes the input sequence and creates a rich, contextual representation.
- Decoder: Not used in BERT, as BERT focuses on understanding rather than generation.
Attention Mechanism
The key innovation in Transformers, and by extension in models like BERT, is the attention mechanism. This mechanism allows the model to dynamically weigh the importance of different words in a sentence when making predictions rather than relying on a fixed context window as in traditional models.
Self-Attention
At the heart of the attention mechanism is self-attention, also known as scaled dot-product attention. Self-attention lets the model consider the entire input sequence when processing each word. In simpler terms, when the model processes a word, it looks at all other words in the sentence. It assigns different levels of importance (or attention) to each of them, helping it understand the relationships between words.
For example, in the sentence, “The cat sat on the mat,” the word “cat” might pay more attention to “sat” and “mat” than “the” because those words are more relevant to the meaning of the sentence.
Self-attention is computed using three learned matrices:
- Query (Q): Represents the word we are currently focusing on.
- Key (K): Represents every other word in the sentence.
- Value (V): Holds the information about the words themselves.
The model calculates attention scores by comparing the Query and Key matrices to see how much attention each word should get in relation to the word being processed. These scores are then used to weight the Value matrix, which contains the actual information about the words. The model uses this weighted information to understand the input.
Multi-Head Attention
Multi-head attention builds upon the self-attention mechanism by applying multiple attention mechanisms in parallel. Each attention mechanism, or “head,” learns to focus on different aspects of the relationships between words. For example, one head might focus on direct word-to-word relationships (like subject-object), while another might focus on the syntactic structure (like identifying adjectives related to nouns).
Using multiple heads, the model captures a richer understanding of the sentence’s meaning, enabling it to represent more complex word interactions. The outputs from each attention head are then combined and processed, giving the model a more nuanced understanding of the input.
In summary, attention mechanisms, especially self-attention and multi-head attention, allow models like BERT to process and understand sentences more effectively by considering the context of every word in relation to the entire sequence.
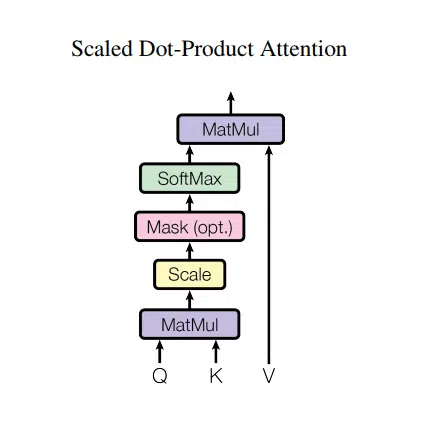
BERT’s Adaptation of the Transformer Architecture
BERT builds upon the Transformer architecture with specific adaptations to suit the task of language understanding better. Here’s how BERT modifies the core Transformer model:
Multi-Head Attention
In BERT, multi-head attention plays a central role in capturing the relationships between words. The idea is that multiple attention heads can focus on different types of relationships simultaneously (e.g., subject-object pairs or grammatical structure). After each head computes the attention scores, BERT concatenates the results of all attention heads and passes them through a final dense layer (a fully connected neural network layer). This step allows BERT to combine the different perspectives learned by each attention head, giving the model a more comprehensive understanding of the input.
By integrating multiple views of attention from different heads, BERT gains deeper insights into the interactions between words in the sentence.
Encoder-Only Architecture
While the original Transformer model contains both an encoder and a decoder, BERT simplifies this using only the encoder. This is because BERT’s primary goal is to understand language rather than generate it. Encoders are better suited for tasks like classification, question answering, and sentence completion, where understanding the input text is crucial.
In contrast, tasks like text generation (e.g., machine translation) rely on the decoder portion of the Transformer. Since BERT focuses on understanding, it drops the decoder entirely, making the model more efficient for its intended tasks.
Bidirectional Context
One of the significant breakthroughs in BERT is its ability to consider bidirectional context. Earlier models, such as GPT, processed text in one direction—either left-to-right (predicting the next word based on previous words) or right-to-left. This unidirectional approach limits the model’s context when interpreting a sentence.
BERT, however, looks at the entire sentence simultaneously. This allows the model to understand the context of each word based on both the words that come before it and the words that come after it. For example, in the sentence, “The bank raised interest rates,” the word “bank” can refer to either a financial institution or a riverbank. BERT’s bidirectional context enables it to interpret the word “bank” based on the surrounding words, leading to a better understanding of the sentence as a whole.
Stacked Encoders
BERT consists of multiple stacked Transformer encoder blocks, another key adaptation. Each encoder block contains two main components: a multi-head attention layer and a feed-forward layer. The multi-head attention layer allows BERT to capture relationships between words in different contexts. In contrast, the feed-forward layer processes the results of the attention mechanisms, learning deeper features about the input data.
By stacking these encoders, BERT can build progressively more sophisticated representations of the input text. Each layer refines the understanding of the sentence, allowing the model to capture local and global relationships within the text. The more encoder layers BERT has, the better it becomes at learning complex patterns and dependencies within the language.
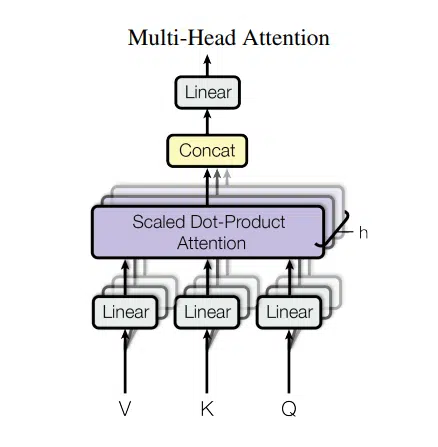
- Encoder-Only: BERT uses only the encoder part of the Transformer, as its primary goal is language understanding, not generation.
- Bidirectional Context: Unlike previous models that processed text either left-to-right or right-to-left, BERT considers the entire context simultaneously.
- Stacked Encoders: BERT consists of multiple stacked Transformer encoder blocks, each containing a multi-head attention layer and a feed-forward layer.

BERT comes in two main configurations:
- BERT Base: 12 layers, 12 attention heads, 768 hidden units, 110 million parameters
- BERT Large: 24 layers, 16 attention heads, 1024 hidden units, 340 million parameters
This architecture allows BERT to create deep, context-rich language representations, enabling its strong performance across various NLP tasks.
Transfer Learning with BERT
BERT revolutionized NLP by introducing a powerful transfer learning approach, similar to the paradigm shift seen in computer vision with ImageNet and deep convolutional neural networks [1].
Pre-training and Fine-tuning
- Pre-training: BERT is initially trained on a massive corpus of unlabeled text, learning general language representations
[1]. - Fine-tuning: These pre-trained representations can then be adapted to specific NLP tasks with minimal additional training
[1].
This two-step process allows BERT to:
- Capture general language understanding from a large, diverse dataset.
- Quickly adapt to specific tasks, even with limited labelled data.
Versatility in NLP Tasks
BERT’s pre-trained representations are remarkably versatile, supporting a wide range of NLP tasks:
- Sentence-level tasks: Classification, sentiment analysis, natural language inference.
- Token-level tasks: Named entity recognition, part-of-speech tagging, question answering.
Efficiency in Learning
The power of BERT’s transfer learning approach lies in its efficiency:
- Resource Efficiency: Fine-tuning requires significantly fewer computational resources than training from scratch.
- Data Efficiency: State-of-the-art results can be achieved on smaller, task-specific datasets.
- Time Efficiency: Adaptation to new tasks is much faster than training a model from scratch.
Parallel to Computer Vision
This approach mirrors the successful transfer learning strategies in computer vision:
- In CV: Models pre-trained on ImageNet are fine-tuned for specific image recognition tasks.
- In NLP: BERT, pre-trained on large text corpora, is fine-tuned for specific language tasks.
Both approaches leverage large-scale pre-training to learn general features, which are then efficiently adapted to more specialized tasks.
By providing rich, contextual pre-trained representations, BERT enables even simple models to achieve state-of-the-art performance on various NLP tasks, democratizing access to advanced NLP capabilities.
How Do They Do It?
Input/Output
BERT uses a summation of three embeddings as an input representation. This input allows single sentences or a pair of sentences to be represented as one token sentence. A token embedding maps the natural language sequence to a numerical representation. A segment embedding indicates whether a token belongs to sentence A or B. A positional embedding tells the model where the token is in the sequence. The sequences are decorated with unique tokens:
- The Classification token [CLS] indicates the final hidden state of the sequence representation for classification tasks.
- The Separation token [SEP] indicates whether a token belongs in sentences A or B.
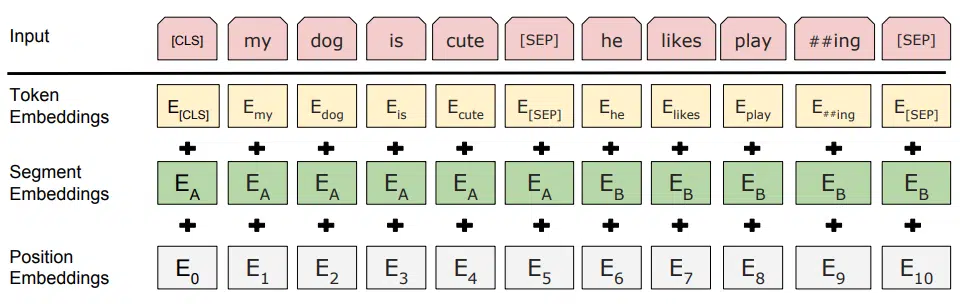
The Issue of Sequential Training
Using a Transformer allows the entire input sequence to be processed simultaneously, avoiding the sequential dependencies found in recurrent neural networks. The attention mechanism helps capture relationships across the whole sequence. However, when training language models with Transformers, the task is often to predict the next word in a sequence, which introduces a directional bias. BERT addresses this by using two strategies: Masked Language Modeling (MLM), where random words are hidden, and the model predicts them based on surrounding words, and Next Sentence Prediction (NSP), which helps the model understand relationships between sentences. These approaches allow BERT to learn the context in both directions, removing the inherent directionality in traditional language models.
Masked LM
Masking 15% of tokens: In BERT’s training process, 15% of the tokens in each input sequence are selected for masking. However, instead of always replacing these tokens with the special [MASK] token, they follow the pattern you described:
- 80% of the time, the token is replaced with the
[MASK]token. - 10% of the time, the token is replaced with a random token from the vocabulary.
- 10% of the time, the original token is left unchanged.
This helps prevent the model from overfitting to the [MASK] token during training since that token won’t appear during fine-tuning or real-world tasks.
Prediction process:
- After the encoder processes the sequence, a classification layer is added to the output vectors corresponding to the masked positions.
- These output vectors are projected to the vocabulary size by multiplying them with the embedding matrix (the same matrix used to convert tokens into embeddings).
- Finally, a softmax function is applied to predict the probability distribution over all possible words in the vocabulary for each masked position.
This approach allows BERT to predict the original words at masked positions while learning contextual information from both the left and right sides of each token. The absence of an ablation study regarding the specific 80-10-10 split is also true, as no exhaustive experiments were performed to identify the ideal masking ratio.
Next Sentence Prediction
In the Next Sentence Prediction (NSP) task, BERT is trained to determine whether a second sentence follows the first in the original text or if it is a random sentence from the same document. During training:
- 50% of the input pairs consist of consecutive sentences, where the second sentence is the actual following sentence.
- The other 50% consists of pairs where the second sentence is randomly selected from the document, making it unrelated to the first sentence.
The model learns this using the special [CLS] token, which is added at the beginning of each sentence pair. The output representation from this [CLS] token is fed into a classification layer, which uses a softmax function to predict whether the second sentence is the true next sentence or a random one.
During training, BERT optimizes a combined loss function that includes both:
- The Masked Language Modeling (MLM) loss, where the model predicts masked words in the input.
- The Next Sentence Prediction (NSP) loss, where the model predicts whether the second sentence follows the first.
Both losses are minimized simultaneously, allowing BERT to learn bidirectional context and sentence relationships effectively.
Extracting Features from BERT
One of the exciting aspects of BERT is its ability to generate fixed features from the pre-trained model, similar to how Word2Vec or ELMo produce word embeddings [4][5][1]. The key difference with BERT is the added context provided by its bidirectional training approach, which results in richer feature representations. These context-aware features can be used for downstream tasks that traditional models like Transformers might not as easily handle.
Notably, the expensive pre-training process for BERT only needs to be done once. Once pre-trained, BERT can be fine-tuned or used to extract features for various tasks at a much lower computational cost. This makes BERT a highly flexible model for tasks like Named Entity Recognition (NER), where the paper showed that BERT’s feature-based approach outperforms other state-of-the-art models [1].
This capability makes BERT a powerful building block in many NLP pipelines, enriching models with robust, contextually-informed embeddings without repeating the computationally expensive pre-training phase.
Ablation Studies: What Makes BERT Tick?
Feature ablation is a common practice in machine learning research. It involves systematically removing or disabling specific features of a model to assess their individual contributions. By doing so, researchers can rank the importance of different features and determine which ones have the greatest impact on model performance. Metrics like F1 score, accuracy, and loss are typically used to measure performance in feature ablation studies.
In the BERT paper, the researchers conducted a feature ablation study by removing key components, such as the Next Sentence Prediction (NSP) task and Masked Language Modeling (MLM), and tested the performance of these variants on five different pre-training tasks. This helped to identify which features were crucial for BERT’s success.
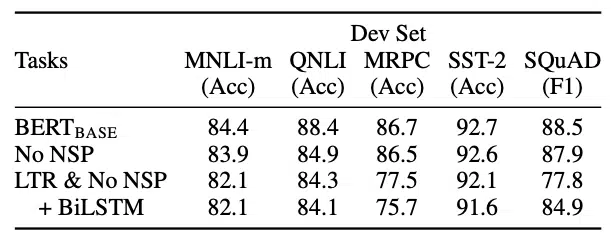
Feature Ablation Study Results
- No NSP: This model variant uses the masked LM but does not include the Next Sentence Prediction task. The absence of NSP significantly impacts tasks like Natural Language Inference (NLI) and Question-Answering (QA), demonstrating that NSP plays a crucial role in understanding sentence relationships.
- LTR & No NSP: In this configuration, neither masked LM nor NSP is used. Instead, the model predicts tokens in a left-to-right (LTR) manner, similar to the OpenAI GPT model. Removing bidirectionality in this way leads to a noticeable drop in performance across all tasks, indicating that BERT’s bidirectional context is essential for its strong results.
- + BiLSTM: This configuration adds a randomly initialized bidirectional LSTM layer on top of the LTR & No NSP model. While this reintroduces some context on both sides of a token, performance only improves for the Question-Answering task (SQuAD) as a right-side context is regained. However, this configuration still performs much worse than BERT’s original bidirectional architecture, highlighting the strength of BERT’s pre-trained bidirectional approach.
- Overall, the complete BERT base model—which incorporates both masked LM and NSP—demonstrates consistent and high performance across the five tested NLP tasks, underscoring the importance of each feature in BERT’s design.
What is the Trade-off Using BERT?
While BERT is a powerful model for many NLP tasks, it comes with some trade-offs:
- Fine-tuning instability: BERT can be sensitive during fine-tuning, especially when working with small datasets. This instability can result in inconsistent performance, with the model sometimes failing to converge or delivering suboptimal results. To mitigate this issue, careful tuning of hyperparameters and learning rates is often required.
- Computational intensity: Pre-training and fine-tuning BERT are computationally expensive processes. Pre-training BERT from scratch requires vast amounts of data and GPU/TPU resources, and even fine-tuning can be resource-intensive, especially for larger variants of BERT, such as BERT-large. This can make BERT less accessible for organizations or individuals without significant computational infrastructure.
- Maximum sequence length: BERT has a maximum input length of 512 tokens. While this is sufficient for many tasks, it can be a limitation for others, such as document classification or tasks that involve processing longer texts. For tasks requiring longer sequences, models like Longformer or approaches like splitting long inputs into chunks are often used as alternatives.
These trade-offs mean that while BERT is highly effective, it may not always be the best choice, depending on the task, dataset size, and computational resources available.
BERT’s Impact and Successors
BERT’s release sparked a wave of innovation in natural language processing (NLP), leading to the development of several notable successors:
- RoBERTa [6]: Demonstrated that BERT was undertrained and achieved better results by training on more data and using more compute. RoBERTa refined BERT’s training procedures, showing that increased training time and batch sizes could significantly boost performance.
- ALBERT [7]: Introduced parameter-sharing techniques across layers, drastically reducing the model’s size while maintaining performance. ALBERT achieved state-of-the-art results on several benchmarks with far fewer parameters than BERT.
- DistilBERT [8]: A smaller, faster, and more efficient version of BERT that retains about 97% of BERT’s performance while being nearly 60% smaller and twice as fast. DistilBERT is widely used in resource-constrained environments.
- T5 [9]: Took a novel approach by framing all NLP tasks as text-to-text problems. T5 achieved state-of-the-art results across various benchmarks, illustrating the versatility of treating tasks like translation, summarization, and classification under a unified framework.
- GPT-3 [10]: While not directly based on BERT, GPT-3 showcased the power of scaling models to billions of parameters, pushing the boundaries of language generation and understanding. GPT-3 demonstrated the ability to perform tasks with few-shot or zero-shot learning.
- GPT-4 [11]: Marked a significant leap forward in language models, with remarkable advancements across various tasks.
- Multimodal capabilities: GPT-4 can process text and images, broadening its applicability [11].
- Improved reasoning: It displays enhanced problem-solving abilities, making it more effective at tasks requiring complex reasoning [11][12].
- Increased context window: GPT-4 can handle much longer input contexts than BERT, making it suitable for tasks involving extensive text sequences [11].
- Ethical considerations: GPT-4 was designed to focus on safety and alignment with human values, reflecting a broader shift towards ethical AI deployment [11].
Despite these advancements, BERT-style models remain relevant for many tasks, especially where bidirectional context is essential and computational efficiency is a priority. For tasks like question-answering or named entity recognition, BERT and its successors continue to perform strongly, making them valuable tools in the NLP landscape.
How Can I Implement BERT?
You can easily use BERT with libraries like Hugging Face Transformers [13]. Here’s a simple example of sentiment classification:
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# Load pre-trained model and tokenizer
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Prepare input
text = "I love machine learning!"
inputs = tokenizer(text, return_tensors="pt")
# Forward pass
outputs = model(**inputs)
# Get prediction
prediction = torch.argmax(outputs.logits).item()
print(f"Sentiment: {'Positive' if prediction == 1 else 'Negative'}")
In this example:
- We load a pre-trained BERT model and a BERT tokenizer.
- The input text is tokenized and converted into tensors for PyTorch.
- The model processes the input using a forward pass.
- Finally, the predicted sentiment is obtained by selecting the class with the highest logit score.
This example uses the bert-base-uncased model from Hugging Face, which is pre-trained and can be fine-tuned for tasks like sentiment analysis.
Conclusions
BERT marked a significant milestone in NLP, introducing groundbreaking concepts such as bidirectional pre-training and proving the effectiveness of the Transformer architecture for language understanding. Although more recent models have surpassed BERT in performance on many tasks, its impact on the field remains profound. Mastering BERT provides a strong foundation for understanding current and future NLP developments.
As we’ve seen with the rapid progress from BERT to models like GPT-4, the NLP landscape continues to evolve at an astonishing pace. However, the core principles introduced by BERT—particularly self-attention and the power of pre-training—are still central to many of today’s cutting-edge models.
Thank you for reading this post on BERT. Stay tuned for more paper summaries, and as always, happy researching!
References
[1] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” arXiv preprint arXiv:1810.04805, 2018.
[2] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” 2018.
[3] A. Vaswani et al., “Attention Is All You Need,” in Advances in Neural Information Processing Systems, 2017.
[4] Y. Bengio, R. Ducharme, P. Vincent, and C. Janvin, “A neural probabilistic language model,” Journal of Machine Learning Research, 2003.
[5] M. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2018.
[6] Y. Liu et al., “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” arXiv preprint arXiv:1907.11692, 2019.
[7] Z. Lan et al., “ALBERT: A Lite BERT for Self-supervised Learning of Language Representations,” arXiv preprint arXiv:1909.11942, 2019.
[8] V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter,” arXiv preprint arXiv:1910.01108, 2019.
[9] C. Raffel et al., “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,” Journal of Machine Learning Research, 2020.
[10] T. B. Brown et al., “Language Models are Few-Shot Learners,” arXiv preprint arXiv:2005.14165, 2020.
[11] OpenAI, “GPT-4 Technical Report,” arXiv preprint arXiv:2303.08774, 2023.
[12] A. Kojima et al., “Large Language Models are Zero-Shot Reasoners,” arXiv preprint arXiv:2205.11916, 2022.
[13] T. Wolf et al., “Transformers: State-of-the-Art Natural Language Processing,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2020.

Suf is a senior advisor in data science with deep expertise in Natural Language Processing, Complex Networks, and Anomaly Detection. Formerly a postdoctoral research fellow, he applied advanced physics techniques to tackle real-world, data-heavy industry challenges. Before that, he was a particle physicist at the ATLAS Experiment of the Large Hadron Collider. Now, he’s focused on bringing more fun and curiosity to the world of science and research online.