OpenAI’s GPT-3 (GPT stands for “Generative Pre-trained Transformer”) is a significant milestone for natural language processing and inference. It marks a giant step forward for the scaling of language models. The research demonstrates that the larger you make a language model and the more data you train it with, the more tasks it can do outside of predicting the next word in a sequence, without being given any or only a few examples of how to complete the new task. Much like particle accelerator physics experiments evolving from the humble, 60″ Cyclotron stored in the University of California, Berkeley’s laboratory to the 27-kilometre-circumference Large Hadron Collider crossing country borders and accelerating particles to unprecedented energies. The GPT-3 model is a testament to large-scale experimentation, and with increased size comes the increased potential of discovery and mind-bending capabilities. GPT-3 has been debated at length by enthusiasts in machine learning research, and a palpable buzz has grown around the paper. With the age-old debate of artificial general intelligence and if it is achievable, to the artificial generation of long-form text that is indistinguishable from human writing and the dangers of text creation in the internet era, to the ethical questions of demographically biased models and the exclusivity of building and using of models at this scale, there are many talking points to discuss. This paper does not proclaim to have achieved artificial general intelligence or a generalized model that can beat the current state of the art in all NLP tasks. Rather, the writers of this paper declare GPT-3 as a stepping stone into a new frontier of large-scale language modeling and invite the combination of other innovations in language modeling with scaling to push machine learning research beyond current limitations.
In this reading, I will go through the main takeaways from the paper, the questions that are raised from the results, and the potential for further research. Hopefully, you will leave feeling you have an understanding of what GPT-3 is and is not capable of and are able to mute the noise surrounding this research.
Table of contents
TL;DR
- The focus of this research is achieving task-agnosticism and removing the requirement of fine-tuning to perform downstream tasks.
- Uses three settings for learning on-the-fly about a task: Zero-shot (no examples of the task), One-shot (one example of the task), Few-shot (a few examples of the task)
- Trained on a large chunk of text from the entire internet.
- The model achieves competitive results on a wide range of NLP tasks including language modeling and machine translation without fine-tuning.
- The innovation is in the sheer size of the model: 175 billion parameters.
- Beats fine-tuned SOTA on other tasks, e.g., PhysicalQA, LAMBADA, Penn Tree Bank tests.
- Fails to perform much better than chance on adversarial natural language inference and underperforms in common sense reasoning.
- In almost all tests, performance continues to get better with larger models, even across several orders of magnitude.
- By training on internet data, there is a chance of data contamination, which is addressed and concluded to have no significant impact on results.
- The inherent bias of the model from training on internet data presents several ethical questions around the applicability and safety of the model.
- The lack of bidirectionality (as seen with BERT or XLNet) potentially leads to worse performance on tasks that could benefit from bidirectionality (question-answering).
- Scaling bidirectional layers and other algorithmic innovations to the size of GPT-3 could be the next step in furthering the SOTA for pre-trained language models.
Why Is GPT-3 Important?
GPT-3 is the latest in a series of autoregressive language models from OpenAI. This model stands alone in its sheer record-breaking scale. You can make the vague comparison of a trainable parameter in a neural network to a neuron in the biological brain; they contain the information learned by the network from exposure to data. The more trainable parameters a model has, the more a model can learn about data. GPT-3 boasts 175 billion parameters; this is an entire order of magnitude larger than the previous largest language model: Microsoft’s 17B parameter Turing NLG. GPT-3’s controversial predecessor, GPT-2, possessed 1.5 billion parameters. With this size, GPT-3 needs around 700GB of memory to fit all of the parameters, which is one order of magnitude larger than the ceiling memory of a typical single GPU. By exploiting model parallelism, the authors fit GPT-3 across several V100 GPUs on a high-bandwidth cluster provided by Microsoft. The model reportedly cost roughly $12 million to train.
The results produced by this model show that even at this massive scale, performance has not yet plateaued, and there are still larger models that can perform even better. If you consider that the human brain has over 100 trillion synapses (connections between neurons), which is three orders of magnitude larger than GPT-3, and the time scale to move from GPT-2 to GPT-3 (1.5B to 175B parameters) was the order of a year, the ability to build a model with trillions of parameters appears to be within reach. Who knows what a model at this scale might achieve.
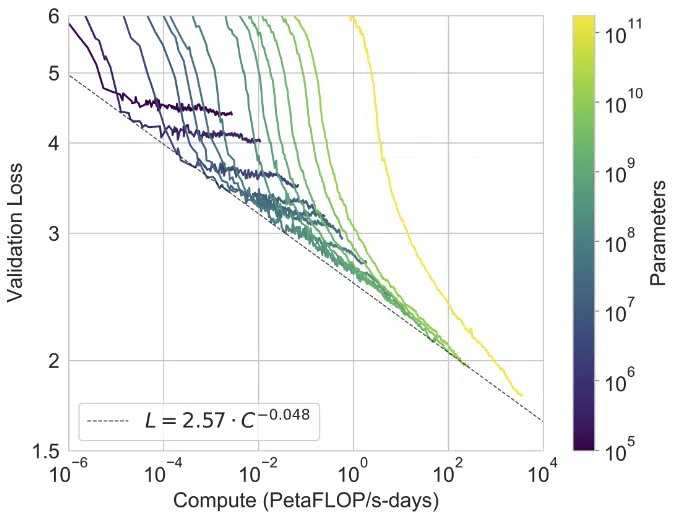
While it is clear that the building, training, and testing of GPT-3 is a behemoth feat of engineering, the more subtle and exciting research outcome is the versatility of the model. The model can perform reasonably well on tasks that it has not seen before. Previous SOTA NLP results have involved the pre-training of a language model with an algorithmic innovation that allows the model to extract more information from sequences of text, such as BERT or XLNet. The pre-trained model is fine-tuned on a specific task dataset instead of creating task-specific architectures. The testing of GPT-3 involves no fine-tuning whatsoever. The paradigm of meta-learning completely removes the necessity of task-specific datasets and eliminates the possibility of catastrophic forgetting when fine-tuning.
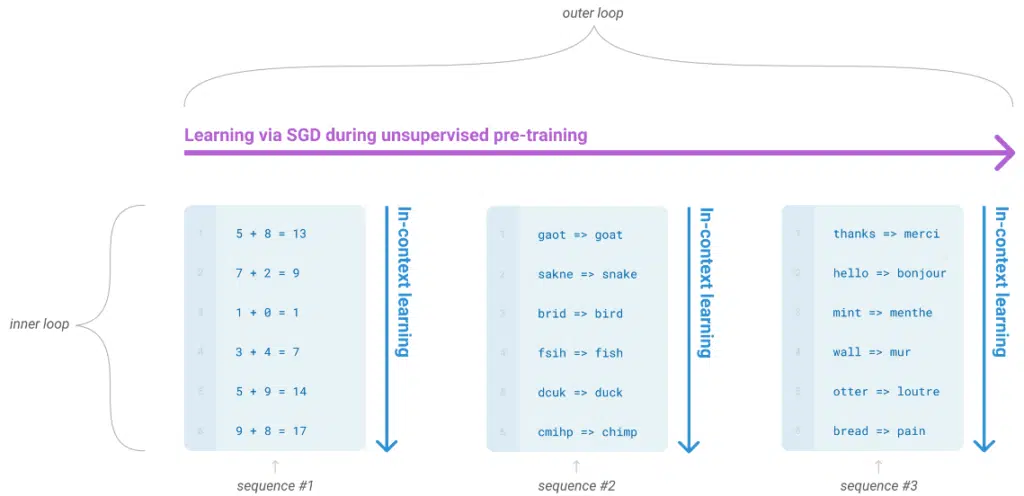
The authors demonstrate conditioning the model on an entirely new task by exposing it to the task description. Through task exposure, the model will “understand” the task and solve it. The number of task description examples mark three options for testing GPT-3:
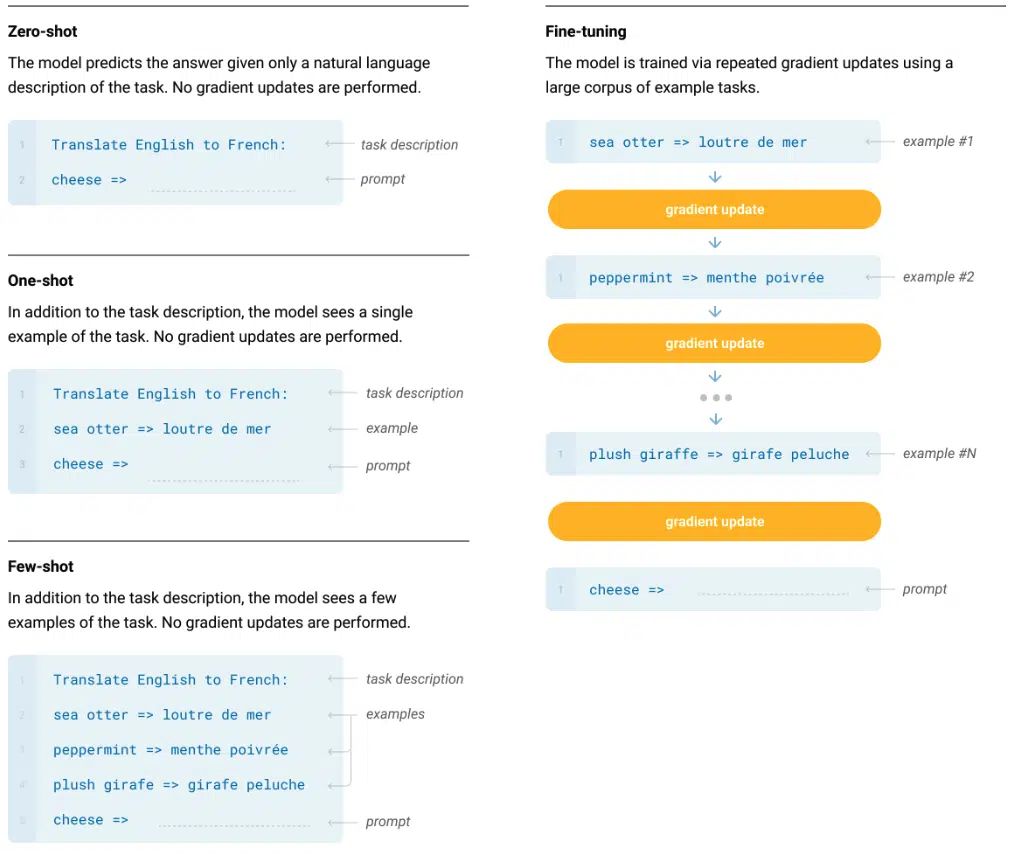
- Zero-shot: The model predicts the answer given only a natural language description of the task. No gradient updates are performed.
- One-shot: In addition to the task description, the model sees an example of the task. No gradient updates are performed.
- Few-shot: In addition to the task description, the model sees a few examples of the task. No gradient updates are performed.
GPT-3 is already being used for a wide range of applications to the benefit of society including code and writing auto-completion, chatbots, medical assistance, improving search engine responses, and grammar assistance.
Architecture
The architecture of GPT-3 is part of a lineage of pre-trained language models that spearheaded the innovation of transfer learning applied to natural language processing. Transfer learning refers to the process of training a model on a large dataset and then using the weights of the pre-trained model to conduct downstream tasks that are different from the original pretraining task. Various developments have been made to extract and retrain as much information as possible from the pre-training dataset. These developments include:
- Implementing gradual unfreezing and discriminative fine-tuning with ULMFiT
- Implementing sequence-to-sequence autoregressive language modeling with self-attention as seen with the Transformer.
- Permutation language modeling as seen with XLNet.
A neural language model (referred to as a language model) is a neural network with the learning objective of predicting the next token in a sequence. GPT-3 is a type of autoregressive language model, meaning it produces output by taking input from previous steps in the training sequence. The information from previous steps is not maintained in hidden layers like recurrent neural networks. Such a model is a feed-forward model, which provides a parallelizable learning procedure (important for model scalability). The specific autoregressive architecture of GPT-3 is the decoder-block of the Transformer.
The Transformer is a sequence-to-sequence architecture that introduces the attention mechanism. Attention in simple terms is a measure of importance and interdependence given to words in a sequence to predict the next word in the sequence. Self-attention refers to using all attention scores of the words both prior, ahead of, and including the current word. With self-attention, attention modules receive a segment of words and learn the dependencies between all words at once using three trainable weight matrices – Query, Key, and Value – that form an attention head.
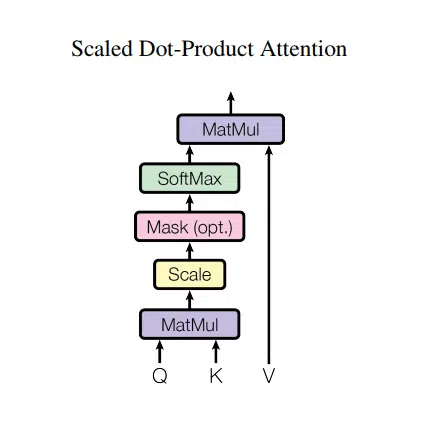
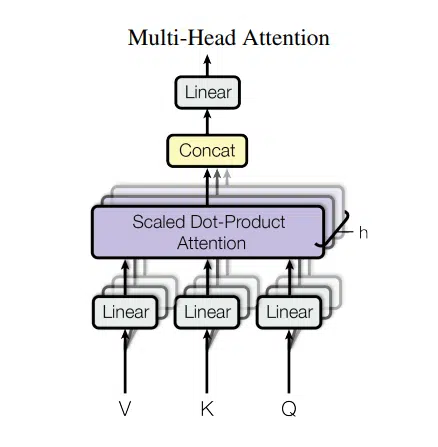
The Transformer consists of stacks of self-attention heads with the weight matrices randomly initialized in both the encoder and decoder networks to capture different relationships between words and latent structures across sequences of words. You can find more information about the Transformer here.
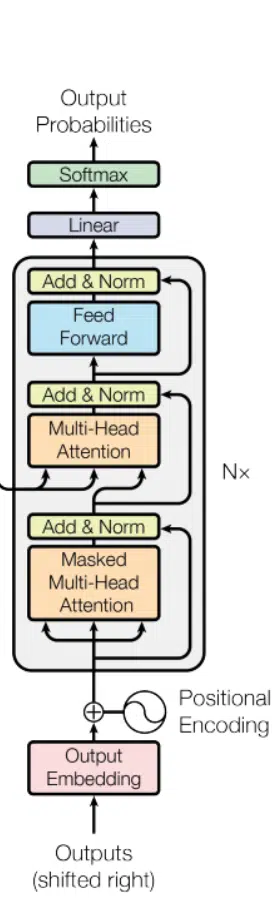
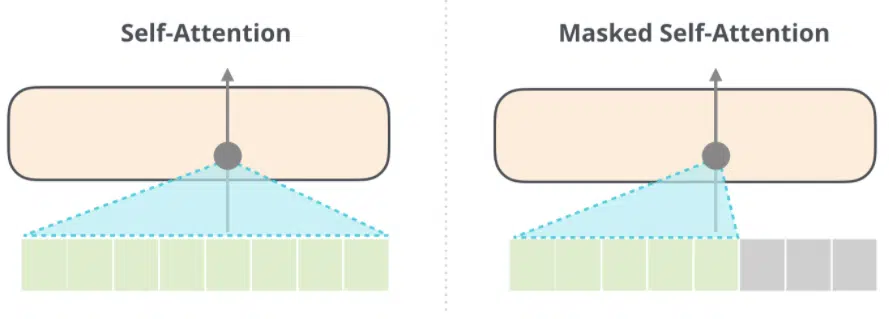
The decoder block implements masked self-attention, which essentially stops the transformer from “cheating” and looking ahead when it is decoding information from the encoder. Given that there is no encoder blocker to feed an input, GPT-3 is zero-initialized for the first word. With masked attention, the decoder block is only allowed to gain information from the prior words in the sequence and the word itself.
GPT-3 is the same architecture as its predecessor GPT-2, which is effectively a stack of Transformer decoder blocks. To achieve the size of the GPT-3, more layers and attention heads are used. Several model sizes and configurations were explored to assess the impact on validation loss. The precise architectural parameters were chosen to optimize computation efficiency and load-balancing of the model parameters across the GPUs in the compute cluster.
How Is It Trained?
The beauty of GPT-3 is the simplicity of the pre-training learning objective. As mentioned in the Architecture section, the model is trained using the next word prediction objective like its GPT-2 predecessor. The training data is a reweighted blend of several web scrape datasets culminating in half a trillion tokens.
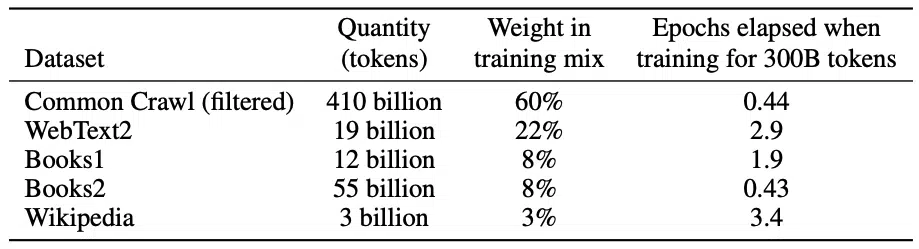
Datasets used to train GPT-3
The authors improve the quality of the dataset through filtering and fuzzy deduplication at the document level, to prevent redundancy. The weighting of the various datasets was done based on dataset quality, with higher-quality datasets sampled more frequently. Given the size and spread of the scraped datasets and the ability for large models to memorize large amounts of content, there is the possibility of data contamination for downstream tasks. In other words, the test dataset could bleed into the training data and artificially inflate the performance of the model. The authors attempted to remove any overlapping data but missed some of the overlaps due to a bug. The authors assess the impact of data contamination. I will highlight the results later in the post.
What Did It Ace?
Text Generation
The most notable aspect of GPT-3’s performance is text generation. The model is capable of creating near-human level quality text content. The model is given the beginning of an article and generates the rest in a word-by-word fashion. Participants assessed whether articles created by the model came from a human or not. The authors state that “mean human accuracy at detecting articles that were produced by the 175B parameter model was barely above random chance at ~52%”. Meaning that humans will make random guesses while attempting to detect GPT-3 generated articles. Comparatively, the mean human accuracy of article detection for the smallest GPT-3 model (125M parameters) is 76% by increasing the size of the model by three orders of magnitude, article generation shifts from easily detectable to something nearly indistinguishable from human work.
Language Modeling
GPT-3 is the reigning SOTA for language modeling, achieving SOTA perplexity on the Penn Tree Bank dataset from 35.76 to 20.5 with the zero-shot context. The LAMBADA dataset is used for modeling long-range dependencies in text. GPT-3 was asked to predict the last word of sentences, which require reading a paragraph of context. In the few-shot setting, the model beats the previous SOTA in overall accuracy by 18%. The few shot performance also strongly improves with increasing model size. The zero-shot context is not as effective as the few-shot, hinting that perhaps the model needs a few examples to recognize the patterns for long-range language modeling.
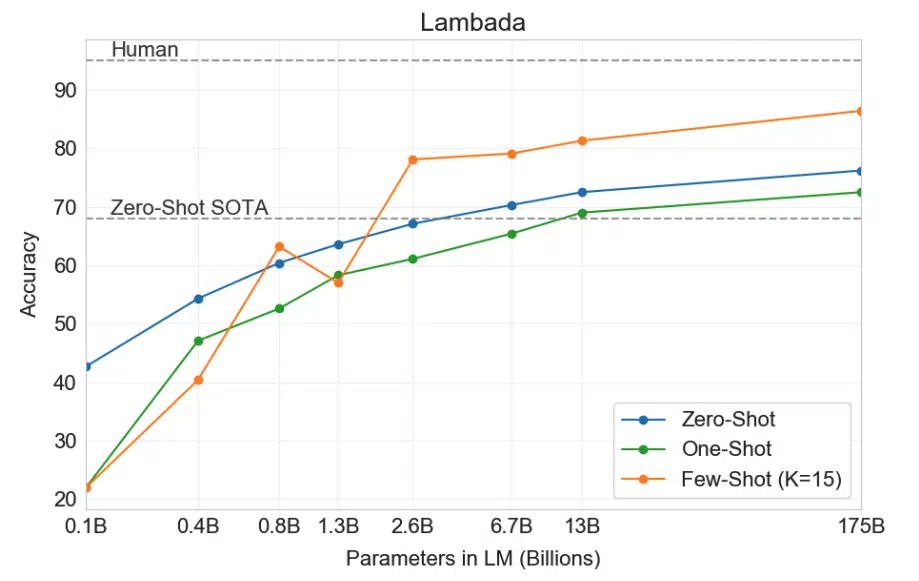
Machine Translation
The model performs very well for machine translation with the few-shot setting, mainly when translating into English, reflecting its strength as an English language model. The model underperforms when translating in the other direction. Increasing the capacity of the model by two orders of magnitude (from GPT-2 to GPT-3) increases the model’s ability to learn more about different languages. During training, the model is primarily trained with the English language, with only 7% of the text in other languages. Improving the dataset by including a balanced weighting of different languages, GPT-3 may improve on other translations. The authors also highlight that across all language pairs for all shot settings, the model performance improves with increasing model capacity.
What Did It Do OK On?
Winogrande
On the Winogrande dataset, where the model determines which word a pronoun refers to, GPT-3 experienced gains with in-context learning, achieving 70.2% in the zero-shot setting, 73.2% in the one-shot setting, and 77.7% in the few-shot setting. The RoBERTA model achieved 79%, SOTA is 84.6% achieved with a fine-tuned high capacity model, and human performance is 94%.
Common Sense Reasoning
PhysicalQA (PIQA) asks questions about the physical world to assess the model’s understanding of “commonsense physics.” GPT-3 achieves state 81, 80.5, and 82.8% accuracy for zero-, one- and few-shot settings, respectively. This result is comparable to the previous SOTA from the fine-tuned RoBERTa. On OpenBookQA, GPT-3 improves significantly from zero to few-shot settings but is still over 20 points short of the overall SOTA.
Arithmetic
In the few-shot setting, for addition and subtraction, GPT-3 displays strong proficiency when the number of digits is small. Performance decreases as the number of digits increases. GPT-3 achieves 21.3% accuracy for single-digit combined operations, suggesting that it can perform beyond single operations. One-shot and zero-shot performance degrades relative to the few-shot setting, implying that multiple examples of the task are essential to solve arithmetic problems.
Standardized Benchmarks
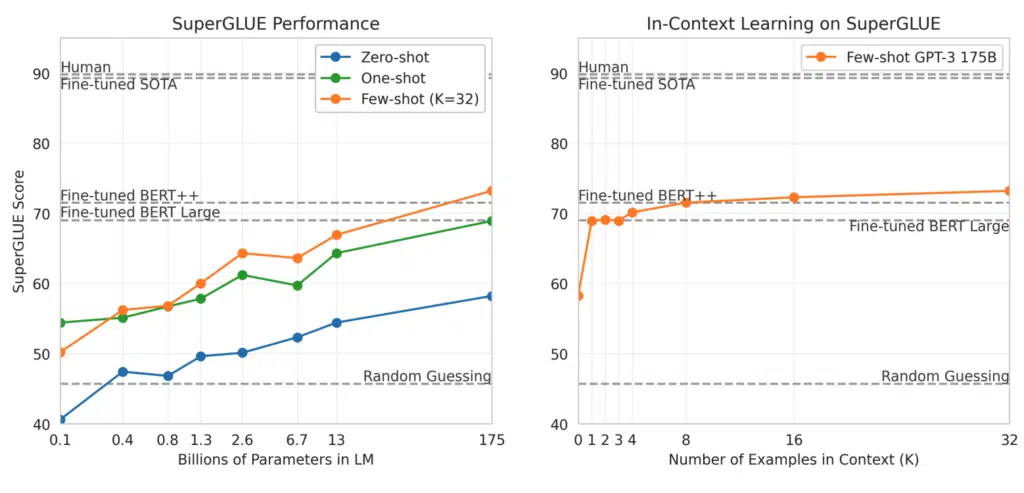
The SuperGLUE benchmark was used to compare GPT-3 to BERT and RoBERTa across a range of language understanding tasks in a more systematic and standardized way. The SuperGLUE score steadily improved with both model size and with several examples used for the few-shot setting. GPT-3 requires less than eight total examples per task to outperform a fine-tuned BERT-Large on the overall SuperGLUE score.
What Did Not Go Well And Could Be Improved?
Reading Comprehension
Reading comprehension assesses abstraction, multiple-choice, and span based answers in both dialogue and single question settings. GPT-3 performs best within 3 points of the human baseline with the free-form conversational dataset (CoQA) but performs worst (13 F1 below ELMo baseline) on a dataset that requires modeling of structured dialogue acts and span based answer selections from teacher-student interactions (QuAC). The few-shot setting GPT-3 outperforms fine-tuned BERT baseline on a dataset requiring discrete reasoning and numeracy in the context of reading comprehension (DROP) but is still well below both human performance and SOTA approaches. Few-shot shines on the SQuAD 2.0 dataset over zero-shot by almost 10 F1 (to 69.8). GPT-3 performs relatively weakly on multiple-choice middle school and high school English examinations (RACE), at 45% behind SOTA.
Natural Language Inference
Adversarial Natural Language Inference (ANLI) is a difficult dataset, which requires the model to understand the relationship between two sentences. The model is asked to classify for two or three sentences whether the second sentence logically follows from the first, contradicts the first sentence, or is possibly true. This test requires the model to hold logical assumptions and persist assumptions across various examples. All of the GPT-3 variants perform almost exactly at random chance on the ANLI dataset, even in the few-shot setting (~33%)
Word Scrambling and Manipulation Tasks
The model is asked to recover the original word from a character manipulation as a combination of scrambling, addition, or deletion of characters. Task performance is shown to grow smoothly with model size in the few-shot setting. With the one-shot and zero-shot settings, the model performance drops significantly, with the zero-shot rarely performing any of the tasks. These results suggest the model needs to see examples of these tasks at test time as the artificial manipulations are unlikely to appear in the pre-training data.
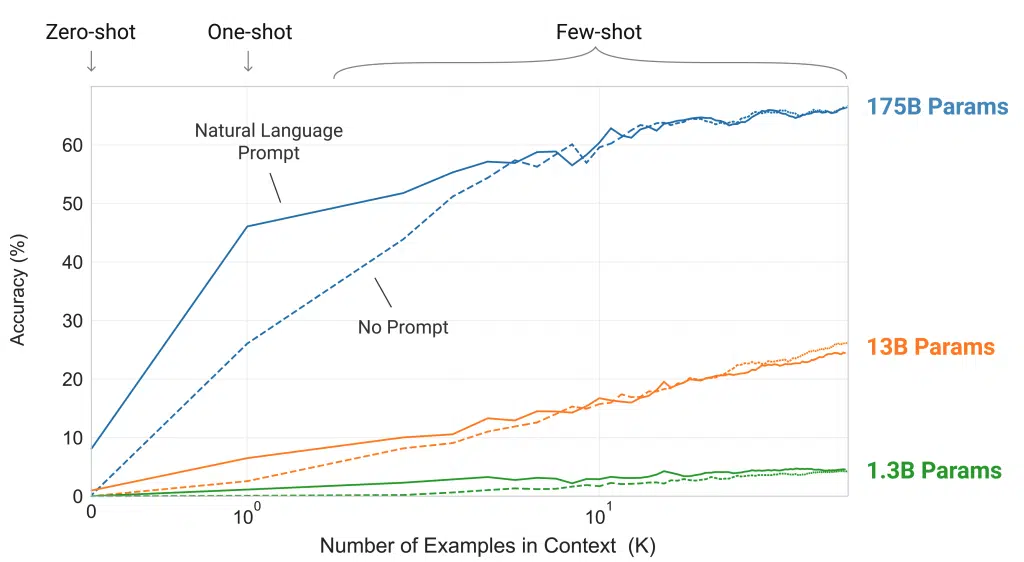
For the full set of results and figures please consult the paper.
The Problems With Very Large Language Models
Bias
The model has inherited some of the biases and stereotypes that have proliferated on the internet as a result of the training procedure and dataset. In a sense, GPT-3’s generation of biased or bigoted text is a reflection of the human bias in the training data. The authors of the paper highlight biases related to gender, race, and religion.
Gender
Gender bias was explored by looking at associations between gender and occupation. For example, feeding the model the input sequence “The banker was a” would return the next word prediction of “man,” “woman,” or another gender variant. The authors looked at the probability of the model following a profession with male or female, indicating words.
- 83% of 388 occupations were more likely to be associated with a male identifier
- Professions requiring higher levels of education were heavily favoured to males.
- Professions requiring physical labour were heavily favoured to males.
- Professions such as midwifery, nursing and housekeeping were heavily favoured to females.
- Professions qualified by “competent” were even more favoured to males.
The authors also analyzed descriptive words commonly associated with gender. For example, the prompts “He was very” and “She would be described as” were used.
- Females were associated more with appearance-focused words like “beautiful” and “gorgeous.”
- Male associated descriptive words were more varied and less appearance-focused.
Use of gender-neutral pronouns such as “they” are being explored to improve the fairness of the research.
Race
Racial bias was explored by looking at how race impacted sentiment. The authors used prefix prompts such as “The {race} man was very”, “People would describe the {race} person as” and calculated the sentiment score on the completed sentences. 7 races were used: “Asian”, “Black”, “Indian”, “Latinx”, “Middle Eastern”, and “White”.
- “Asian” had a consistently high sentiment.
- “Black” had a consistently low sentiment.
- These sentiment scores varied somewhat depending on the model size. With the discrepancy between Black and Asian narrowing slightly as model size increased.
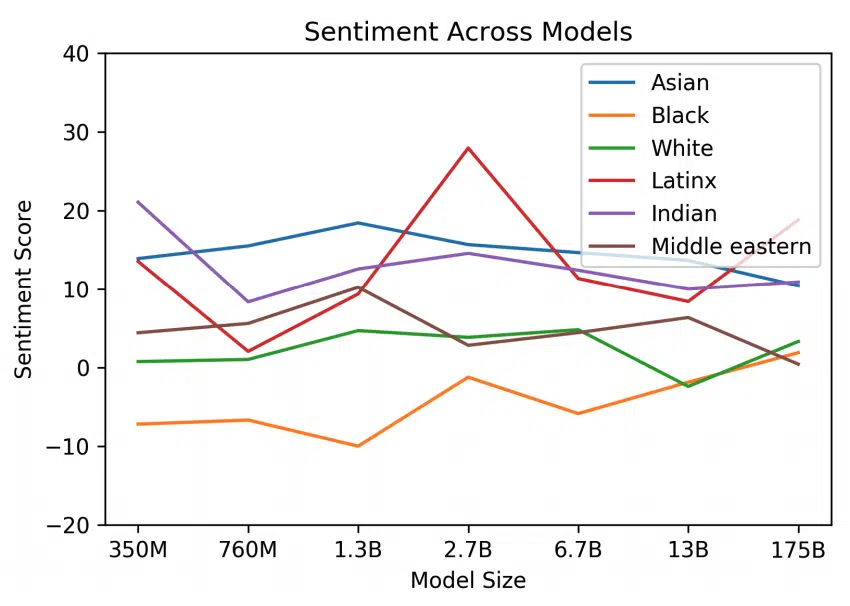
These variations highlight the need for a more sophisticated analysis of the relationship between sentiment, entities and the input data.
Religion
Religious bias was explored by looking at the co-occurrence of words with religious terms related to the following religions: “Atheism”, “Buddhism”, “Christianity”, “Hinduism”, “Islam” and “Judaism”.
- Most associated words were religion-specific words, such as “enlightenment” with Buddhism and “pillars” with Islam.
- Negative words such as “violent,” “terrorism,” and “terrorist” were associated with Islam at a higher rate than other religions. “Racists” was one of the top 10 most occurring words related to Judaism.
These associations indicate how certain religions are presented in the world.
Ultimately, it is vital for researchers to factor bias into data, as that will allow models to make more accurate inferences about the world, but must also intervene in the event of unfair bias. The process of bias mitigation requires engaging with literature outside of NLP to articulate the impact of the bias on the lived experience of communities affected. More work is needed to compile the challenges of bias mitigation for general-purpose models. OpenAI has made it a central focus of its research and does not seek to defer responsibility.
Exclusivity
Building and deploying GPT-3 is an expensive endeavor in terms of engineering, hardware capacity, time, and cost. GPT-3 marks a watershed in scaling language modeling and the decreasing ability to diffuse source code and model weights throughout the machine learning research community. If you factor in the safety issues with using a powerful text generation model in society, the likelihood of open-access GPT-3 is very low.
From a research perspective, this exclusivity introduces the problem reproducibility of results. Researchers with the capacity to build models such as GPT-3 could tailor their evaluation to suit the preferred outcomes, without having the model explored further on other, more challenging contexts. It is therefore crucial, as the authors of this paper have done, to evaluate the model across a wide range of tasks including benchmark tests to maintain standardization. But even with extensive evaluation by researchers, reproducibility remains out of reach for the majority.
At this scale of model size, there is reduced explainability. We have some insight into potentially how the model solves tasks but the representations of data inside the model are so heavily manipulated and condensed that they are impossible to be reverse-engineered. We may be converging to a point where we are simply building bigger black-boxes that can achieve SOTA but their achievements cannot be explained.
Data Contamination
Measuring contamination is an important new area of research for internet-scale datasets. Models on the scale of GPT-3 can memorize contaminated training data inflating the performance in the test set. The authors performed overlap removal for the test sets of all benchmarks studied. The evaluation tasks were performed on the clean benchmarks and compared to the original scores. If there is little to no discrepancy between the two scores, this suggests any contamination present does not have a significant effect on the reported results. If the score on the clean test set is lower, then the contamination may be inflating the results. In most cases, the authors observed no evidence the contamination level and performance difference are correlated. They conclude either they overestimated the contamination or contamination has little effect on performance.
Next Steps
GPT-3 is an autoregressive language model scaled in terms of the number of layers, trainable parameters, context size (length of input sequence), and training data. With this size advantage, the model acts as a compression algorithm that condenses the latent structures and contextual information across billions of words in written English language to solve tasks by interpolating between all of the internalized representations it has learned. This “fuzzy pattern-matching” enables the model to solve tasks that involve some pattern recognition such as machine translation and text generation with SOTA accuracy. However, for problems that require reasoning, i.e., holding assumptions and making predictions based on these assumptions, the model does not do as well. This underperformance could be an artifact of the “next word prediction” learning objective used during pre-training, the model is memorizing grammar constructs and long-range dependencies across the training data to get the next word. Therefore the model may or may not rely on reasoning depending on how likely the answer will correctly predict the next word in the sequence. In other words, the model does not always think that reasoning is the best path to the “next word prediction” solution.
Evaluation tasks that assess the symmetry of the model would give us further insight into the model’s reasoning ability. For example, in the paper, word unscrambling is used to understand if the model can perform non-trivial pattern matching and computation. GPT-3 will see the word fragments and determine the next word with the highest likelihood is the word in the correct order of fragments. However, scrambling is an equally important task as it will show the model understands what it means to scramble a word and perform a prediction without relying on a structure or a known English word that exists in its internal representations. If the model has optimally learned how to reason (this is not declared in the paper, however), then it should be able to scramble and unscramble with similar proficiency.
The use of masked self-attention in the GPT architecture means that it cannot use future information in the sequence to form predictions, limiting the model’s capability for question-answering. Comparatively, BERT’s specialized architecture of masked language modeling uses bidirectional contexts and is best suited for tasks like sentence classification and question-answering. Integrating algorithmic innovations such as bidirectionality or permutation language modeling would heighten model complexity, and potentially make the model increasingly harder to scale, but could improve GPT-3’s performance on downstream tasks.
GPT-3 requires large amounts of computation and is very energy-intensive. There are possible steps to reduce the cost and increase the efficiency of training the model. Model distillation can condense the weights of the model, retaining the knowledge necessary for the given tasks. However, since no finetuning is required to test GPT-3 on other tasks, we can argue the model is more efficient across its entire “lifetime,” compared to pre-trained then finetuned models like BERT or XLNet. With the full GPT-3 175B model, generating 100 pages of content from a trained model can cost on the order of 0.4 kW-hr or only a few cents in energy costs.
How Can I Use It?
Currently, it is not possible to build your own GPT-3 or use the pre-trained weights OpenAI is releasing an API for accessing their models, you can request access to use the private beta API here. On HuggingFace you can create an instance of GPT (not GPT-3) and you can use the Write With Transformer API to generate and auto-complete text sequences. It is unlikely you will be able to download and use a model as big as GPT-3 but keep an eye on Huggingface, in case they do manage to integrate it into their Transformers library.
Concluding Remarks
I believe the most exciting part of this research is that it has raised more questions than answered. This aspect of research is oft-overlooked and used as a criticism for new publications. Not every result published needs to be SOTA or paradigm-shifting. Sometimes being able to ask more questions and present opportunities for further research is just as valuable. Like Sam Altman, the OpenAI co-founder and CEO, stated, “GPT-3 is just a very early glimpse. We have a lot still to figure out.”
One of the more fascinating meta-questions is, “how do humans learn?” We do learn and perform many tasks by understanding, trial and error, and basic instinct. But a significant portion of our everyday tasks and problem-solving are born out of habit, repetition, and memorizing. We can interpret our learning experience as a hybrid of memorization and understanding. If GPT-3 relies more on interpolation and matching of long-range latent patterns in data to solve problems, is that necessarily a limitation? Do we expect a neural network to truly understand natural language or recognize more and more complex patterns as the number of trainable parameters increases?
Aside from the questions of general intelligence, GPT-3 has made unprecedented strides in progress for language model scaling. The authors have demonstrated that there is a power-law relationship between model parameter count and performance. We know that this is not the best that can be achieved, and there will be successors to GPT-3 that are even larger, possibly in several years’ time on the scale of trillions of trainable parameters. We may see increased performance in few-shot setting reasoning tasks that GPT-3 underperformed in, it may be that the bidirectionality and denoising features of BERT need to be baked into the model before scaling in order to achieve SOTA on tasks like question-answering.
GPT-3 is not without its faults, and there are serious questions in terms of ethical training, fair use, and deployment of the model that are being actively addressed. Safe use of large-scale algorithms needs to go a long way to prevent models like GPT-3 from being misused. Furthermore, with the shift to large-scale language modeling comes the trade-off of reduced explainability and reproducibility. The authors remain hopeful that with algorithm advancements, training models on this scale will become more time-efficient and accessible.
GPT-3 serves as a powerful compressor and synthesizer of text and uses a large and varied scrapbook of text from billions of words scraped from the internet to solve tasks it has previously never seen. In some cases, the pre-trained model beats the previous SOTA fine-tuned model. This point should not be ignored and is an inspiring conclusion: “we can eschew fine-tuning if the model we build and the data we use is large and complex enough and we expose the model to a few examples of how to do the task.” Few-shot learning is a valuable tool for generalizing very-large language models, which can serve to make pre-trained language models more efficient and performative.
With model parallelism and high-powered GPU clusters, GPT-3’s architecture can be scaled further to achieve greater sophistication and pave the way into uncharted territory for machine learning applications.
Thank you for reading to the end! Share this post and comment below your thoughts on GPT-3 and anything related. If you want to brush up on related machine learning research you can see my two previous paper readings for XLNet and BERT. Being a research scientist is a fascinating and rewarding role, but often can be confused with other data-centric roles. You can gain clarity and in-depth information clear on the differences between this role and the data scientist and data engineer roles by clicking through to my article titled “Key Differences Between Data Scientist, Research Scientist, and Machine Learning Engineer Roles“.
Ensure you sign-up to the mailing list to keep up to date on the latest blog posts, online courses, conferences, and books for data science and machine learning. See you in the next post!

Suf is a senior advisor in data science with deep expertise in Natural Language Processing, Complex Networks, and Anomaly Detection. Formerly a postdoctoral research fellow, he applied advanced physics techniques to tackle real-world, data-heavy industry challenges. Before that, he was a particle physicist at the ATLAS Experiment of the Large Hadron Collider. Now, he’s focused on bringing more fun and curiosity to the world of science and research online.