One of the most celebrated, recent advancements in language understanding is the XLNet model from Carnegie Mellon University and Google. It takes the “best-of-both-worlds” approach by combining auto-encoding and autoregressive language modeling to achieve state-of-the-art results on a wide range of Natural Language Processing (NLP) tasks, including question-answering, natural language inference, sentiment analysis, and document ranking. In this paper reading, I will go through the model’s key features and compare its architecture to its predecessors Transformer-XL and BERT.
Table of contents
TL;DR
- XLNET: Generalized Autoregressive Pretraining for Language Understanding is an auto-regressive language model based on the Transformer-XL architecture that has achieved state-of-the-art performance on a wide range of NLP tasks.
- XLNet beats the previously hailed state-of-the-art BERT on selected NLP tasks.
- Proposes permutation language modeling to extract bidirectional representations while avoiding the disadvantages of using data corruption methods in BERT.
- Transformer-XL could be considered an ablation of XLNet, and there is a consistent improvement with XLNet.
- The trade-off is the model is more resource expensive and requires more computation power. BERT is cheaper to train and use.
- XLNet performs better on longer sequences and may underperform on short sequences.
Why is XLNet Important?
XLNet marks a transformative development in NLP and language modeling. Language modeling involves building models that can extract long-range contextual information and salient statistical characteristics from a corpus or body of text sequences. Trained language models predict the next token in a sequence, and the weights can serve as an input to separate models for other NLP tasks. The more semantic information and characteristics a model can extract from a corpus, the more performative a model can be on downstream tasks. State-of-the-art research in NLP centers on optimizing semantic information extraction, examples being ELMo, Transformer-XL, ULMFiT, and BERT.
One of the most significant milestones in this field of research is the introduction of pre-trained deep bidirectional representations of sequences, i.e., learning the contexts of tokens in a sequence from both left-to-right and right-to-left directions. For more details on bidirectionality, see the first of the Paper Reading series titled BERT.
XLNet uses the Transformer-XL architecture, attention, and permutation language modeling to extract deep bidirectional representations, enabling the model to achieve state-of-the-art performance on NLP tasks while improving on learning objectives used in BERT.
Before diving into XLNet, I will go through the essential concepts and predecessors upon which the model is built.
What Is Language Modelling?
Probabilistic language models have the learning objective of predicting the following tokens in a sequence. The probability distribution for sequences of tokens [x1, …., xT] is achieved by factorizing the joint probability into conditional probabilities for each token given other tokens in a sequence using the chain rule of probability:
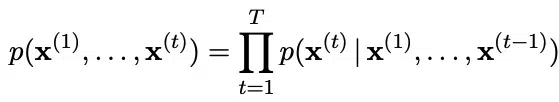
The maximum likelihood objective decomposes into a sequence of prediction problems for each term in the sequence given the previous terms. If these observations are discrete, the prediction can be made using a neural network that outputs a probability distribution over all tokens using a softmax activation function.
Autoregressive language models produce output by taking inputs from previous time steps. The previous inputs are not provided via a hidden state like in recurrent neural nets but are provided as just another input to the model. Such a model is a feed-forward model (i.e., not recurrent), which predicts future values or the next token in a sequence from past values or previous tokens in the sequence. By using autoregression, training is parallelizable, and there is no need for back-propagation through time.
However, autoregressive models are only sequential in nature. The Transformer architecture takes autoregressive language modeling (no hidden state) and eschews sequential learning.
Transformers Explained
The Transformer is a sequence-to-sequence architecture that introduces the attention mechanism. Attention, in simple terms, is a measure of importance given to tokens in a sequence to predict the next step. With attention, instead of processing tokens one by one, attention modules receive a segment of tokens and learn the dependencies between them at once using three trainable weight matrices – Query, Key, and Value – that form an attention head. The Transformer consists of stacks of attention heads with the weight matrices randomly initialized in both the encoder and decoder networks to capture different relationships between tokens.
Attention is effectively non-directional; however, the next word prediction problem is sequential. Positional encoding is used to help the network learn the position of each token. The encoding involves using a sinusoidal function to generate a vector based on a token’s position. This vector is combined with the embedding vector of each token. Attention facilitates the modeling of long-term global context while eschewing recurrence, enables training parallelization, and advanced performance in NLP tasks.
There is a central problem to address with training a Transformer. In a perfect world, we would have infinite memory and computation and thus would map the training sequence to the network in a feed-forward fashion. However, due to finite resources, this is not possible. We can split the training sequence into segments and train the model on each segment. This approach presents two critical limitations:
- The model can only learn for tokens within the segment length and cannot use tokens that appeared several sequences ago. The segment length limits the advantage of using attention.
- Fixed-length segments that exceed the upper bound of segment length are trained separately from scratch. The tokens used to separate segments, i.e., the first tokens of each segment can offer little to no context for the remaining tokens. This behavior is called context fragmentation and leads to inefficient training, which might impact model performance.
The Transformer-XL builds on the vanilla Transformer and introduces two techniques to overcome these limitations:
- Segment-level Recurrence Mechanism
- Relative Positional Encoding
Transformer-XL
The segment-level recurrence mechanism addresses context fragmentation. During training, Transformer-XL caches the hidden state of the previous segment and uses it as an extended context for when the model processes the next segment. The gradient is still within the scope of the segment, but the additional input allows the network to include historical information. This is similar to back-propagation through time, but rather than caching the last hidden state of the sequence, the sequence of hidden states is used.
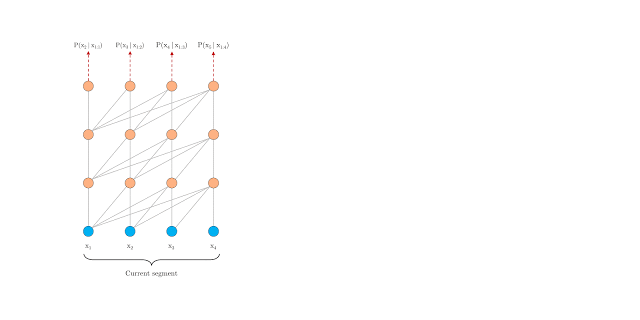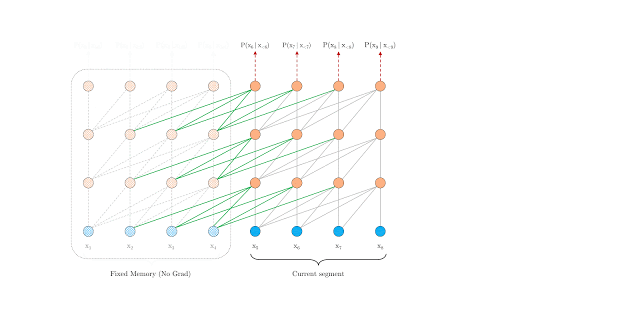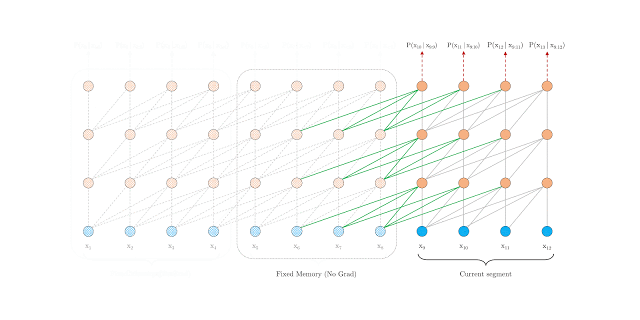
Relative positional encoding is used to persist the positional information for the hidden states of the previous segments. The positional encoding in the vanilla Transformer is lost in the hidden state computation; for example, tokens from different segments could have the same positional encoding, although their position and importance across segments are different.
The encoding involves three changes to the attention score computation:
- Replacing absolute positional encoding with its relative counterpart
- Replacing the query term with a position-independent trainable parameter.
- Separate the weight vectors for producing the content-based and location-based key vectors.
This parameterization is applied to each attention module as opposed to applying a positional embedding before the first layer and accounts for the relative distance between tokens instead of their absolute position.
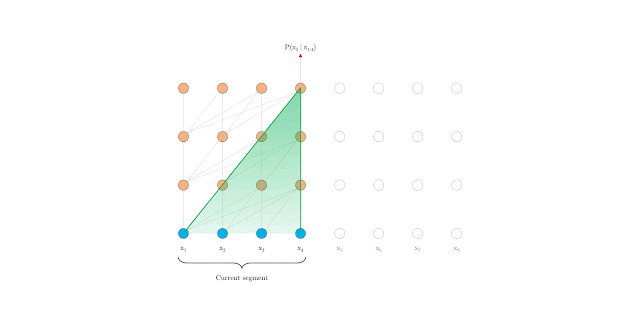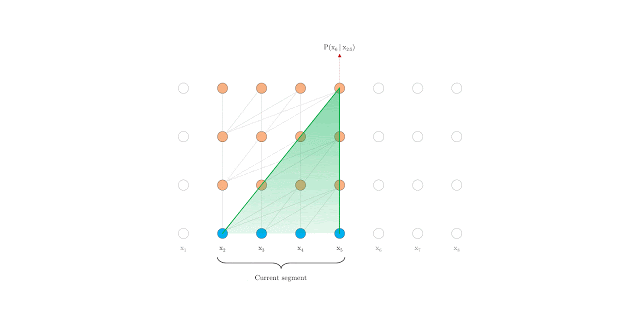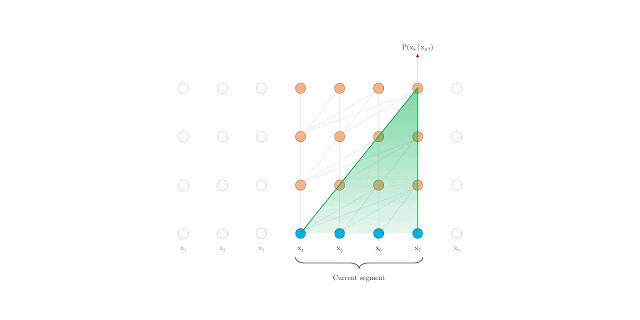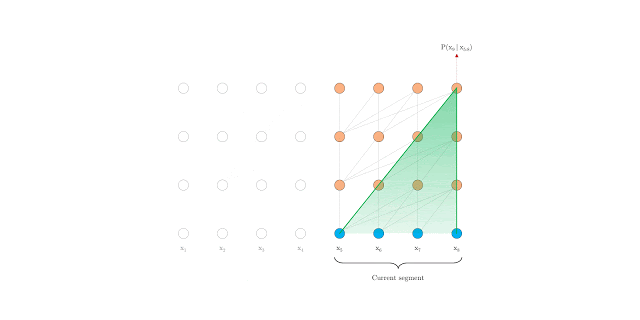

The Transformer-XL outperforms Transformer and RNNs. However, autoregressive language modeling is not able to capture deep bidirectional contextual information like BERT. BERT is defined as an autoencoding pretraining approach that uses data corruption. Autoencoding, in this case, aims to reconstruct original data from a corrupted input. BERT uses bidirectional information to reconstruct partially masked sequences leading to improved performance when compared to the Transformer. However, BERT and the autoencoding approach, in general, has limitations.
The Limitations of BERT
Through the use of data corruption (masking) during pretraining and fine-tuning on actual unmasked data, a discrepancy arises between pretraining and fine-tuning. Furthermore, by eschewing sequential dependencies (as in autoregressive modeling), BERT cannot model with high-order long-range dependencies because it assumes the predicted masked tokens are independent of each other given the unmasked tokens.
The dependence on the masked tokens for pretraining is mitigated by randomly choosing out of the selected tokens to be masked whether they are replaced with
- The [MASK] token (80% of the time)
- A random token (10% of the time)
- The original token (10% of the time)
With this mitigation in place, BERT is still argued in the XLNet paper to provide an over-simplified representation of natural language sequences, despite its triumph in achieving bidirectional context capture. XLNet uses the best of both auto-encoding and autoregressive language models to overcome both of their limitations and improve upon BERT’s performance.
How Does XLNet Work?
Permutations
XLNet improves upon BERT by incorporating bidirectional context capture while avoiding data corruption and parallel independent predictions. It does this by introducing a variant of language modeling called “permutation language modeling“. The order of “next token prediction” is not left-to-right and is sampled randomly instead. This drives the model to learn dependencies between all combinations of inputs, thus modeling bidirectional dependencies.
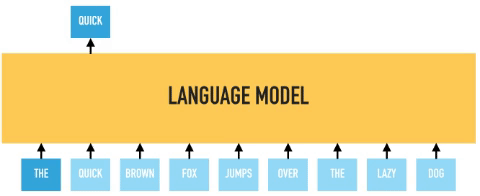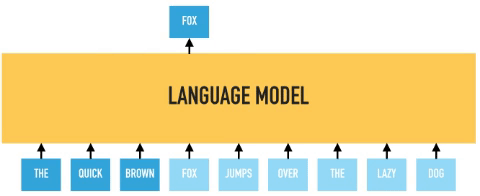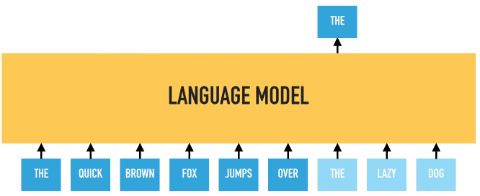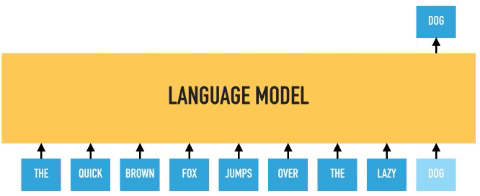
In permutation language modeling, the actual order of the input sequence is not changing, only the order in which the tokens are predicted. We can choose which input tokens to mask and use positional embeddings to retain positional information. Therefore input tokens can be fed into the model in an arbitrary order, and provided the positional embedding are consistent; the model will know the actual order of the tokens.
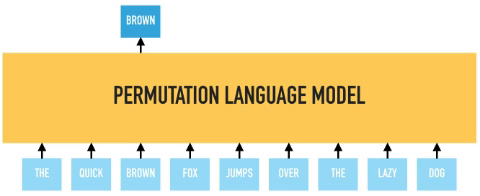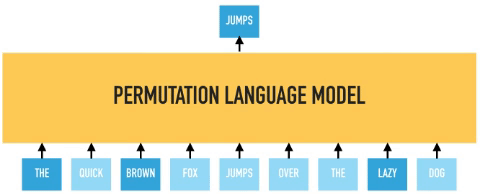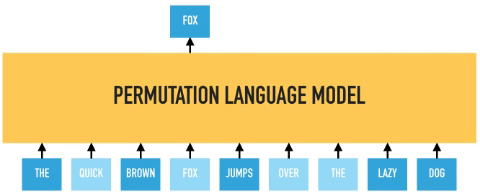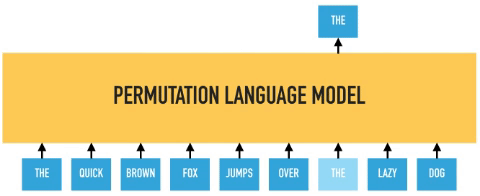
BERT predicts all masked tokens simultaneously and relies on positional encodings to maintain the correct ordering of the tokens. XLNet, on the other hand, learns to predict words arbitrarily. Notice from the figure above how the permutation language model is forced to model directionality (only one possible permutation out of all considered during training).
XLNet uses the relative positional embedding and recurrence mechanism of Transformer-XL to persist hidden state information from previous segments while performing permutation language modeling on the current segment.
While the permutation language modeling learning objective is beneficial for language understanding, it caused slow convergence on preliminary experiments. To improve optimization, the model is trained to predict only a part of the sequence. For tokens not selected for prediction, their positional information is not computed, which saves speed and memory.
The differences between BERT and XLNet can be more explicitly shown if we consider a concrete example [New, York, is, a, city]. If we say, BERT and XLNet take two tokens as prediction targets and maximize the log-likelihood log p( New York | is a city ). Also, if we say XLNet samples the sequence [is, a, city, New, York], the learning objectives of BERT and XLNet can be reduced to:
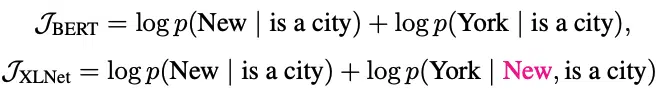
XLNet is able to extract the dependency pair (New, York), which is omitted by BERT. XLNet learns more dependency pairs given the same target and thus obtains denser effective training signals.
Two-Stream Self Attention
Implementing permutation language modeling with the vanilla Transformer model leads to position-independent hidden representations. The next-token probability distribution produced by the model needs to be made target position aware. Two-stream self-attention involves two hidden representations for the attention mechanism to achieve position awareness.
The query stream provides positional information but masks the target token for pretraining. The model is trained to predict each token in the sequence using data from the query stream. The content stream contains the original positional and token embedding; it encodes all the available contextual information for tokens up to the current token. The content serves as input to the query stream.
To provide a simple example, consider predicting the word “fox” in the sentence:
“the quick brown fox jumps over the lazy dog”
The previous words provided in the permutation are “over” and “dog“. The content stream would encode the information for the words “over” and “dog“. The query stream encodes the positional information for “fox” and uses the information from the content stream to predict the word “fox“.
During the fine-tuning process, only the content stream is used as the text representation.
What Are The Benefits Using XLNet?
XLNet beats BERT across twenty tasks, including:
- Text classification
- Question answering
- Document Ranking
- Natural language inference
- Duplicate sentence detection
The model achieves state-of-the-art performance on eighteen out of the twenty tasks. XLNet was compared to more recent adaptions of BERT, including RoBERTa. To compare fairly, the same number of layers and hyper-parameters were used. XLNet’s performance gain was significantly more significant for explicit reasoning tasks like SQuAD and RACE that involve more extended context requirements. XLNet also outperformed RoBERTa substantially on large supervised classification tasks. To see the complete set of results, please refer to the paper.
If I Remove a Part of XLNet, What Happens?
The feature ablation study performed on XLNet shows that it performs better than BERT when using the same training corpus, hyper-parameters, and the number of layers. XLNet also beats its predecessor Transformer-XL in a fair comparison.
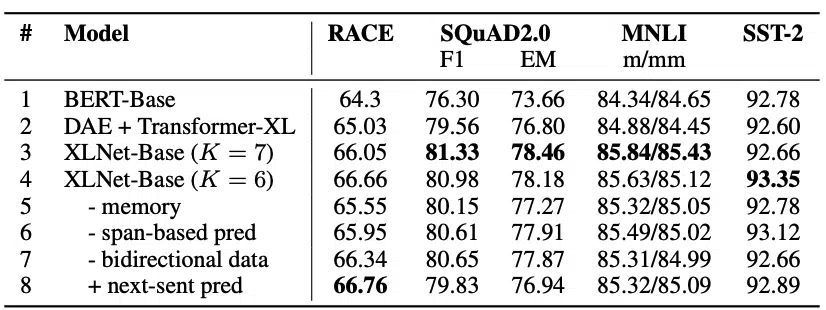
Transformer-XL could be considered an ablation of the permutation language modeling. XLNet does not have the limitations of fixed sequence length and can process sequences of arbitrary length by using the segment-level recurrence of Transformer-XL. Furthermore, XLNet does not use data corruption during pretraining, and as such, no discrepancy arises during fine-tuning as with BERT.
What Are The Drawbacks of XLNet?
XLNet is pre-trained to capture long-term dependencies, and combined with masking during permutation, the model can underperform on short sequences. XLNet is generally more resource-intensive and takes longer to train and to infer compared to BERT. Some NLP tasks can only be run on TPUs with sufficient memory to reach the reported performance. This additional resource requirement is needed to perform the sets of permutations across the input sequences.
Conclusions
XLNet combines the bidirectional capability of BERT with the autoregressive language modeling of Transformer-XL. The model outperforms BERT on various NLP tasks, often by a large margin. The model has been heralded by many as the new standard for language understanding. There are potential applications for XLNet in computer vision and reinforcement learning. For business solutions, XLNet can be used for customer support chat-bots, sentiment analysis, perception awareness, and scraping relevant information from document databases.
How Can I Implement XLNet?
It may be challenging to use XLNet as there is a significant computation power (GPU/TPUs) requirement for fine-tuning the model on the evaluation tasks. However, there are several easy ways to see under the hood XLNet and start your experiments.
- Colab notebook is available to test XLNet on a sentiment analysis task.
- PyTorch wrapper to build and train the model, which will be useful for understanding the model’s functionalities.
- The Hugging Face Transformer library has over 32 pretrained models including XLNet as well as the framework to train your own model.
I hope you enjoyed this installation of the Paper Reading series on XLNet. If you have any questions or exciting research to discuss, please share in the comment section below. Share this post and sign-up to the mailing list for more posts in the future.

Suf is a senior advisor in data science with deep expertise in Natural Language Processing, Complex Networks, and Anomaly Detection. Formerly a postdoctoral research fellow, he applied advanced physics techniques to tackle real-world, data-heavy industry challenges. Before that, he was a particle physicist at the ATLAS Experiment of the Large Hadron Collider. Now, he’s focused on bringing more fun and curiosity to the world of science and research online.