Machine learning is an exciting and rapidly developing field of study centered around the automated improvement (learning) of computer algorithms through experience with data. Through persistent innovation and research, the capabilities of machine learning are now in a realm that would be considered science fiction in the mid 20th century. This post highlights the key milestones that paved the way to modern-day ML and provides some insight into what the future holds for applications of machine learning in society.
Table of contents
- TL;DR
- Conceptualizing Artificial Neurons
- The Turing Test of Intelligence
- Playing Checkers with a Machine
- The Birth of the Perceptron
- The Nearest Neighbours Algorithm
- Bayesian Networks
- Multilayers, Feedforward Networks, and Backpropagation
- Gradient Boosting Algorithms
- Long-Short Term Memory Networks and Support Vector Machines
- Convolutional Neural Networks and Transfer Learning
- Pre-trained Language Models, Attention and Scaling Size of Neural Networks
- The Future of Machine Learning
- Concluding Remarks
TL;DR
- 1943 A human neural network is modeled with electrical circuits.
- 1950 Alan Turing created the world-famous Turing test.
- 1950 A computer program improves its ability to play checkers.
- 1957 The first neuro-computer christened the Perceptron created by Frank Rosenblatt to recognize visual patterns.
- 1967 The nearest neighbor algorithm, the beginning of basic pattern recognition, was conceived.
- The 1960s–1980s Bayesian methods for probabilistic inference developed. Multilayer networks, feedforward neural networks, and backpropagation accelerate processing power and learning capability.
- The 1990s Boosting algorithms developed to reduce bias and create strong learners from ensembles of weak learners.
- The Late 1990s – 2000s Long-Short Term Memory networks developed and outperform traditional speech recognition models. Support vector machines become popular.
- 2010s Deep learning becomes feasible with the arrival of GPUs. The arrival of the ImageNet dataset launches a transformative era of CNN innovation and transfer learning in computer vision.
- 2020 and beyond pretrained language models exhibit state-of-the-art performance across a wide range of natural language processing tasks. GPT-3 175B parameter model adapts to unseen tasks with no weight updates and extends the possibility of scalable language models.
Conceptualizing Artificial Neurons
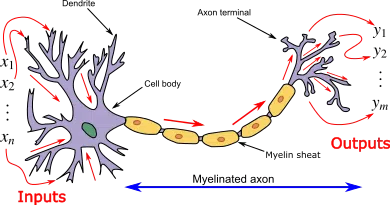
The fundamental unit of deep neural networks is the artificial neuron, which was modeled after the functionality of a biological neuron by McCulloch and Pitts in 1943. In their paper, McCulloch and Pitts tried to understand how the brain could construct intricate patterns using many connected primary cells.
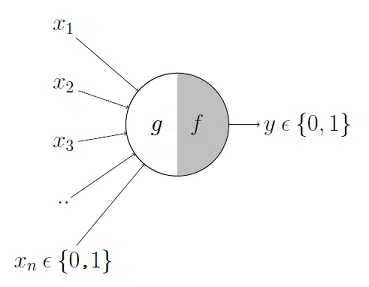
The McCulloch-Pitts neuron has a binary output indicating if the neuron is firing or is at rest. The neuron consists of two parts. The first part, g, is equivalent to the dendrite part of the biological neuron. It takes an input, performs aggregation, and the second part, f, makes a decision based on the aggregated value. The inputs can be either excitatory or inhibitory. Inhibitory inputs always produce an output of 0, i.e., the neuron will not fire. Excitatory inputs, in combination, make the neuron fire and create a non-zero output.
In 1949, Donald Hebb further explored the concept of neurons and learning in The Organization of Behavior. The book explains that neural pathways become more robust with each exposure to a stimulus (Hebbian theory of synaptic plasticity).
The Turing Test of Intelligence
In Alan Turing’s 1950 work entitled Computing Machinery and Intelligence, he proposed the question, “Can machines think?” The Turing test is a recommended method to answer this question or, instead, “Can a machine do what we as thinking entities can do?” A computer can be said to possess artificial intelligence if it can mimic human responses under specific conditions. The test works as a blind interrogation; there are three terminals, each hidden from the other two. One terminal is operated by a computer, while humans run the other two.
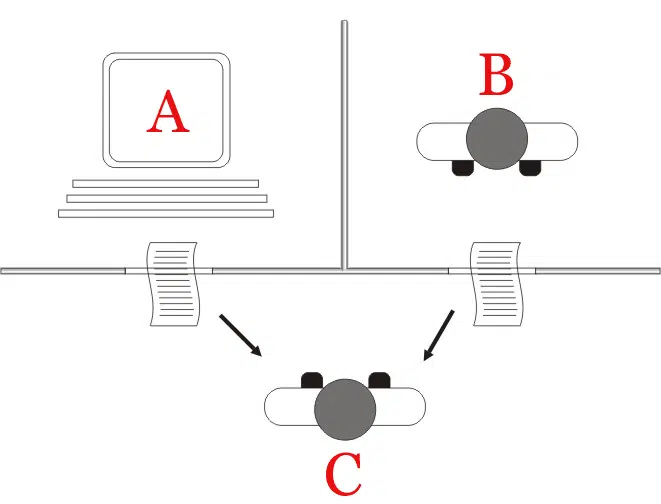
During the test, one of the human operators takes the role of questioner, while the second human and the computer are respondents. The questioner asks a series of questions within a specific subject area, using a specified format and context. The questioner is asked to decide which of the respondents was human. A scoring of correct classification is made over multiple runs of the test. If the questioner correctly classifies the respondents in half of the test runs or less, the computer is considered to have artificial intelligence because the questioner considers the computer a human responder as much as the real human.
Over the years, the Turing test has become less pertinent for understanding artificial intelligence, mainly because of the narrow range of questions used. When questions are more open-ended and beyond “yes” or “no” answers, it is less likely a computer program could successfully fool the questioner. The Turing Test has produced alternatives that include more common sense reasoning, such as the Winograd Schema Challenge.
Playing Checkers with a Machine
Arthur Lee Samuel developed a Checkers program in the 1950s, which could be classed as the world’s first self-learning program. He implemented a variation of the alpha-beta pruning algorithm, which is an adversarial search algorithm that seeks to decrease the number of nodes evaluated by the minimax algorithm in its search tree. Samuel’s program used bitboards to represent the checkers’ board state.

The program was developed for playing on the IBM 701, which was IBM’s first commercial, scientific computer. In 1962, a checkers master Robert Nealey played the program on an IBM 7094 computer and lost. The program is a milestone for artificial intelligence and modern electronic computing.
The Birth of the Perceptron
Almost fifteen years after the McCulloch-Pitts neuron, the American psychologist Frank Rosenblatt created the perceptron in 1958, which took inspiration from the Hebbian theory of synaptic plasticity. Rosenblatt demonstrated that artificial neurons could learn from data and devised a supervised learning algorithm for the perceptron to produce the correct weights to classify from training data. The perceptron can handle only classification tasks for linearly separable classes, which means for nonlinearly separable classes, some feature engineering is required to recast to a linearly separable problem.
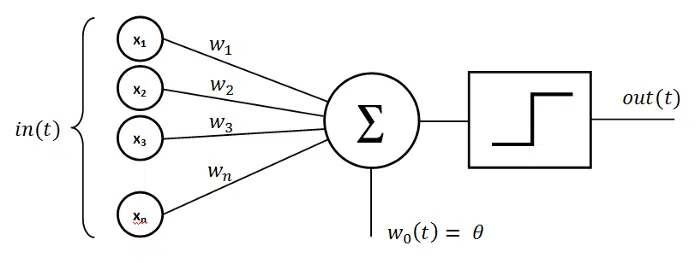
{kind=link}
The Perceptron includes an extra constant input known as the bias, defined as the negative of the activation threshold. The synaptic weights wn are not restricted to unity, allowing for some inputs to have more influence on the neuron output than others. For further reading on activation functions in artificial neural networks, go to the article “An Introduction to the Sigmoid Function“.
The Nearest Neighbours Algorithm
The k-nearest neighbor algorithm (k-NN) is a non-parametric method proposed by Thomas Cover and Peter Hart in their 1967 paper, nearest neighbor pattern classification. The lazy-learning algorithm marks the beginning of fundamental pattern recognition. Initially used for mapping an efficient route to a selected city, starting at a random city, but ensuring all cities were visited en-route.
Bayesian Networks
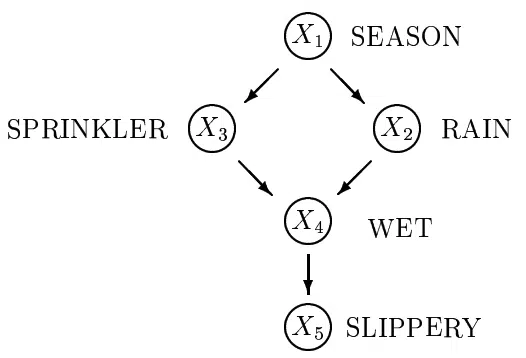
A Bayesian network is a type of probabilistic graphical model, which uses Bayesian inference for probability computation. Developed in the late 1970s by Judea Pearl, Bayesian networks introduce the capability for bidirectional deductions. Bayesian networks aim to model conditional dependence, and consequently causation, by representing conditional dependence with edges in a directed acyclic graph. These relationships allow one to conduct inference on unique random variables (nodes) on the graph. Bayesian networks are ideal for predicting the likelihood of any possible known cause being a contributing factor to a given event. For example, a Bayesian network could give probabilistic relationships between diseases and symptoms.
Multilayers, Feedforward Networks, and Backpropagation
Rosenblatt’s perceptron provided the building blocks for larger functions such as the multilayer perceptron. A multilayer perceptron (MLP) is a deep, artificial neural network composed of more than one perceptron. An MLP can also be referred to as a feedforward neural network. Feedforward networks operate in two motions, a constant back and forth, similar to a game of tennis. The forward pass of a feedforward network is the guess made on a dataset and the backward pass is the feedback to the network to let it know how wrong it was. The degree of how wrong the network was is given by parameterized by a loss function.
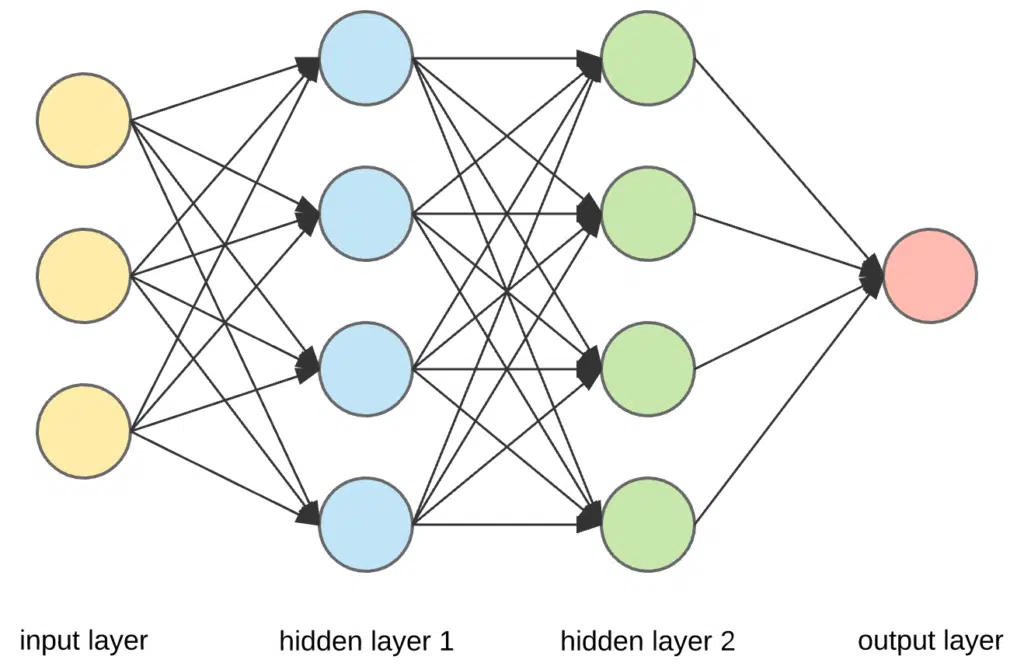
We optimize a feedforward network by minimizing the gradient of the loss function. This process is generically referred to as backpropagation. In 1970, Seppo Linnainmaa published the general method for automatic differentiation (AD) of discrete connected networks of nested differentiable functions. In 1973, Stuart Dreyfus used backpropagation to adapt control parameters (weights) to minimize cost functions. Backpropagation was adapted to the practical training of multi-layer networks by Werbos in 1975. He then applied Linnainmaa’s AD method to neural networks in the way it is commonly used.
In 1986 Rumelhart, Hinton and Williams discovered the importance of the backpropagation algorithm for automating the ability for multi-layer neural networks to create good internal representations for supervised learning tasks. However, the technique was independently discovered multiple times, with several predecessors dating to the 1960s, including Henry J. Kelley in 1960, Arthur E. Bryson in 1961, and Stuart Dreyfus in 1962.
Gradient Boosting Algorithms
Boosting algorithms are used to create a strong learner from an ensemble of weak learners. The concept of weak learnability and boosting was proposed in the 1990 paper titled The Strength of Weak Learnability by Robert Schapire. We refer to weak learners as classifiers that are only slightly better than random guessing, e.g., decision trees. A strong learner is arbitrarily well classified into the correct classification.
The first boosting algorithm that saw much success was the Adaptive Boosting or AdaBoost algorithm in 1995. The weak learners in AdaBoost are decision trees with a single split, commonly called decision stumps. AdaBoost works by weighting the observations by the decision stumps, putting more weight on difficult to classify instances, and less weight on examples that are classified well. The algorithm incorporates weak learners sequentially with their training focused on complicated patterns. In 1999 a statistical framework called Gradient Boosting Machines was developed by Friedman, which generalized boosting beyond binary classification to solve regression and multi-class problems.
Long-Short Term Memory Networks and Support Vector Machines
Recurrent neural networks (RNNs) were based on David Rumelhart’s work in 1986 and are defined as networks with loops, allowing for information to persist over time. RNNs have memory and keep track of information observed previously, making them well suited for sequential data. However, RNNs come with the flaw of vanishing and exploding gradients. These problems arise due to the influence of a given input on the hidden layer, and therefore on the network output, either decaying or blowing up exponentially as it goes through the network’s recurrent connections.
Long-Short Term Memory (LSTM) is an artificial recurrent neural network (RNN) architecture proposed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber to deal with the vanishing and exploding gradient problem. The LSTM solves the two problems by using an additive gradient structure, enabling the network to encourage desired error gradient minimization using frequent updates on every time step of the learning process. LSTM models are widely used in modern applications and have achieved state-of-the-art performance in speech and handwriting recognition, sequence generation, and machine translation.
Another successful ML innovation that became popular in the 1990s is Support vector machines (SVM). SVMs are a supervised learning method for binary classification and regression. The original concept was invented by Vladimir Vapnik in 1963 to address a problem with logistic regression. SVMs are motivated by the principle of optimal separation, i.e., a good classifier finds the largest gap possible between data points of different classes. In 1992, Bernhard Boser, Isabelle Guyon, and Vladimir Vapnik developed a way to create nonlinear classifiers by applying the kernel trick to maximum-margin hyperplanes. The kernel trick allows for operations in the original feature space without computing the coordinates of the data in a higher-dimensional space.
Convolutional Neural Networks and Transfer Learning
In 2009, Fei-Fei Li created an extensive image dataset called ImageNet. ImageNet and the subsequent challenge called ImageNet Large Scale Visual Recognition Challenge (ILSVRC) were significant components responsible for driving popularity and the use of deep learning neural network techniques. ImageNet consisted of 14 million human-annotated photos, with roughly 21,000 groups or classes and roughly 1 million images with bounding box annotations. The challenge involved image classification, single-object localization, and object detection.
Groundbreaking performance across computer vision tasks became achievable through the combination of the vast ImageNet dataset, the innovation of large (deep) convolutional neural networks (CNNs), and the availability of graphical processing unit (GPU) hardware. Milestone model architectures, such as AlexNet, Inception, and VGG, were developed, which, when trained on ImageNet, provided a wealth of pretrained state-of-the-art weights that could be frozen and reused for downstream computer vision tasks. The distribution of powerful yet expensive models made deep learning widely accessible to general users and marked the widespread use of transfer learning to solve problems.
Pre-trained Language Models, Attention and Scaling Size of Neural Networks
Language modeling is defined as predicting the next token in a sequence of tokens. For a model to be able to predict the next token accurately, it is required to learn about syntax, semantics, and physical world reasoning. Given enough data, a large number of trainable parameters, and training time, a model can achieve good accuracy on language modeling. Pre-trained language models provide encodings of long-range contextual information from unlabeled text and, therefore, can be used to solve downstream tasks via transfer learning. Transfer learning in NLP started with stand-alone word embeddings and then evolved into the sophisticated pretrained language models commonly used today.
The late 2010s marked the era of pre-trained language model innovation both in terms of architectural features and scaling model parameters and training data. The introduction of the attention mechanism in the 2017 paper Attention Is All You Need, helped boost model training speed and improve pre-trained representations. Attention and the Transformer architecture fostered further innovation with bidirectional encoder representations from Transformers (BERT) and permutation language modeling (XLNet). The papers for ERNIE 2.0, GPT-2 8B and RoBERTa, demonstrate that training a language model for a more extended period and on more data improves results.
In 2020, OpenAI’s breakthrough paper Language Models are Few Shot Learners demonstrated that language models could be scaled to the order of 175 billion parameters, achieving state-of-the-art in text generation, language modeling, and machine translation. The researchers apply the GPT-3 model to a wide range of NLP tasks without fine-tuning; it only needs to see examples of how to solve a given task, highlighting the potential to generalize artificial intelligence. The paper also demonstrates that even at this size, the performance of the model is not near plateauing, meaning the language model can be scaled further, with continual improvements. The 2020s mark a watershed moment for the scaling of language models, zero and few-shot learning, and the applications of NLP in society. For more information on GPT-3, refer to my earlier blog post titled “Paper Reading #3: ‘Language Models are Few-Shot Learners,’ GPT-3 Explained.”
The Future of Machine Learning
We will see several trends in the future for machine learning. Machine learning will likely become integral to every software application to enhance customer experience and personalization. As machine learning becomes increasingly valuable, more businesses will provide cloud offerings of machine learning as a service (MLaaS), which will, in turn, lower the entry-level to take advantage of machine learning and negate the need for expensive hardware and computations.
With active developments being made in NLP, computers are incredibly adept at understanding natural language. Accurate detection of context and common sense reasoning is achievable through recent innovations in language modeling. Bots will become more streamlined and be able to communicate seamlessly with humans without coding under the hood. We will start seeing more generative models like GPT-3 creating code and long-form text from scratch. We will see models continue to grow in size (order of hundreds to thousands of billions of trainable parameters) and compute, and see continual performance improvement on a wide range of tasks.
Topological data analysis, particularly persistent homology, will become increasingly prevalent in machine learning research. We can leverage topological features (shape) of data to analyze high dimensional and complex datasets, provide dimensionality reduction methods, determine similarities of anisotropies across various surfaces, and more.
Machine learning algorithms will become more online and fluid, meaning supplied training data will continue to evolve over time. Connected AI systems will enable machine learning algorithms to continuously learn by retraining on emerging information on the internet.
Hardware will become more specialized, with other AI accelerators becoming more prevalent, like Intelligence Processing Units or Tensor Processing Units. With the wide range of specialized hardware continuing to improve, the hardware will become more affordable and accessible to organizations, increasing the likelihood of breakthroughs in all applications of machine learning. Sociologically, as machine learning algorithms become more prevalent in society, the ethics of training and using algorithms will become an increasingly dominant topic.
Reinforcement learning has proven to be an exciting and rapidly developing field of machine learning research. Google DeepMind has produced phenomenal algorithms such as AlphaGo, which is a deep reinforcement learning algorithm that taught itself how to play Go and beat the world’s best. AlphaFold is a protein folding algorithm, which is one of the most important goals pursued by computational biology and is important for medicinal applications such as drug design and biotechnology such as novel enzyme design. Reinforcement learning has promise for equally impactful research in many aspects of everyday life, business and industry. To dig deeper into reinforcement learning, start with my article titled “The History of Reinforcement Learning“.
Concluding Remarks
Thank you for reading to the end of this post! Hopefully, this summary of the past eighty highlights just how rapidly developing and bursting with innovation modern machine learning is. This timeline is not exhaustive, so I invite you to dig further into other machine learning research and industry achievements. At the Research Scientist Pod, we focus on exciting and noteworthy research in our “Paper Readings.” You can start with the first Paper Reading titled “Paper Reading #1 – BERT“. To learn more about what is involved in being a research scientist and the differences between that role and the role of a data scientist or data engineer, please click through to my article titled “Key Differences Between Data Scientist, Research Scientist, and Machine Learning Engineer Roles“. If you want to start your path to becoming an expert in machine learning you can find the best online machine learning courses here. See you in the next post!

Suf is a senior advisor in data science with deep expertise in Natural Language Processing, Complex Networks, and Anomaly Detection. Formerly a postdoctoral research fellow, he applied advanced physics techniques to tackle real-world, data-heavy industry challenges. Before that, he was a particle physicist at the ATLAS Experiment of the Large Hadron Collider. Now, he’s focused on bringing more fun and curiosity to the world of science and research online.